

Úvod do príkazov o iskre
Apache Spark je framework postavený na vrchole Hadoopu pre rýchle výpočty. Rozširuje koncepciu MapReduce v scenári založenom na klastroch na efektívne vykonávanie úlohy. Príkaz Spark je napísaný v jazyku Scala.
Hadoop môže byť Sparkom využitý nasledujúcimi spôsobmi (pozri nižšie):
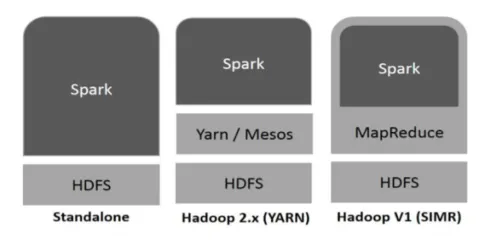
Obr
https://www.tutorialspoint.com/
- Samostatný: Spark priamo nasadený na vrchole Hadoopu. Spark úlohy bežia paralelne na Hadoop a Spark.
- Hadoop YARN: Spark beží na priadzi bez potreby akejkoľvek predinštalovania.
- Spark v MapReduce (SIMR): Spark v MapReduce sa používa na spustenie iskry okrem samostatného nasadenia. S SIMR je možné spustiť Spark a používať jeho shell bez administratívneho prístupu.
Súčasti iskry:
- Jadrové jadro Apache
- Spark SQL
- Spark Streaming
- mLib
- Graphx
Resilient Distributed Datasets (RDD) sa považuje za základnú dátovú štruktúru príkazov Spark. RDD je nemenná a má iba na čítanie. Všetky druhy výpočtov v iskrových príkazoch sa uskutočňujú prostredníctvom transformácií a akcií na RDD.
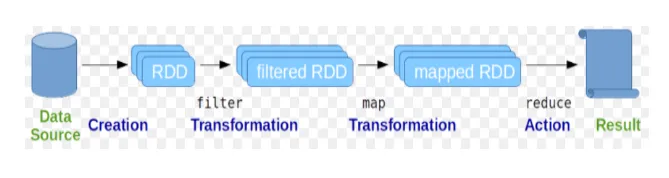
Obr
Google obrázok
Spark shell poskytuje užívateľom prostredie na interakciu s jeho funkciami. Príkazy iskier majú veľa rôznych príkazov, ktoré je možné použiť na spracovanie údajov v interaktívnom prostredí.
Základné príkazy iskry
Pozrime sa na niektoré zo základných príkazov Spark, ktoré sú uvedené nižšie: -
-
Na spustenie prostredia Spark:

Obr
-
Čítať súbor z lokálneho systému:

Tu je „sc“ iskry kontext. Ak vezmeme do úvahy „data.txt“ v domovskom adresári, bude sa čítať takto, inak je potrebné zadať úplnú cestu.
-
Vytvorte RDD prostredníctvom paralelizácie

NewData je teraz RDD.
-
Spočítajte položky v RDD

-
collect
Táto funkcia vracia všetok obsah RDD do programu ovládača. To je užitočné pri ladení v rôznych krokoch programu písania.
-
Prečítajte si prvé 3 položky z RDD

-
Uložte výstupné / spracované údaje do textového súboru

Tu je výstupná zložka aktuálna cesta.
Príkazy pre stredné iskry
1. Filtrujte na RDD
Vytvorme nový RDD pre položky, ktoré obsahujú „áno“.

Na existujúci RDD je potrebné zavolať transformačný filter, aby sa filtrovalo na slovo „áno“, čím sa vytvorí nový RDD s novým zoznamom položiek.
2. Reťazová prevádzka

Tu sa vykonala transformácia filtra a akcia počítania spolu. Toto sa nazýva reťazová prevádzka.
3. Prečítajte si prvú položku z RDD

4. Spočítajte oddiely RDD
Ako vieme, RDD sa skladá z viacerých oddielov, je potrebné počítať nie. skupín. Pomáha pri ladení a odstraňovaní problémov pri práci s príkazmi Spark.

V predvolenom nastavení je minimum č. oddiel je 2.
5. pripojiť sa
Táto funkcia spája dve tabuľky (element tabuľky je párový) na základe spoločného kľúča. V RDD v pároch je prvým prvkom kľúč a druhým prvkom hodnota.
6. Vyrovnávacia pamäť súboru
Vyrovnávacia pamäť je optimalizačná technika. Ukladanie do vyrovnávacej pamäte RDD znamená, že RDD zostane v pamäti a všetky budúce výpočty sa vykonajú na tých RDD v pamäti. Šetrí čas načítania disku a zlepšuje výkon. Stručne povedané, skracuje čas na prístup k údajom.

Ak však spustíte nadradenú funkciu, údaje sa neuložia do vyrovnávacej pamäte. Dôkazom toho je návšteva webovej stránky:
http: // localhost: 4040 / storage
Po dokončení akcie sa RDD uloží do vyrovnávacej pamäte. Napríklad:

Jedna funkcia, ktorá funguje podobne ako cache (), pretrváva (). Persist poskytuje používateľom flexibilitu pri zadávaní argumentu, ktorý môže pomôcť ukladať údaje do vyrovnávacej pamäte v pamäti, na disku alebo mimo haldy. Pretrvávať bez argumentov funguje rovnako ako vyrovnávacia pamäť ().
Pokročilé príkazy na iskrenie
Pozrime sa na niektoré z pokročilých príkazov Spark, ktoré sú uvedené nižšie: -
-
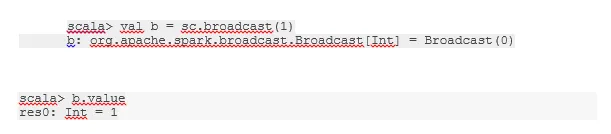
Vysielajte premennú
Premenná Broadcast pomáha programátorovi čítať jedinú premennú uloženú vo vyrovnávacej pamäti na každom počítači v klastri namiesto toho, aby kópiu tejto premennej odosielala spolu s úlohami. Pomáha to znižovať náklady na komunikáciu.
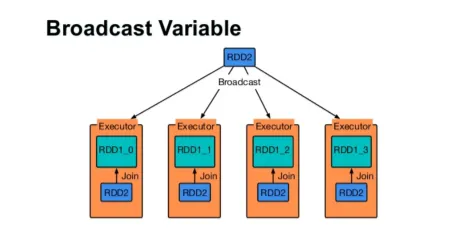
Obr
Google obrázok
Stručne povedané, existujú tri hlavné črty vysielanej premennej:
- nemeniteľný
- Zapamätajte si pamäť
- Distribuované prostredníctvom klastra
-
akumulátory
Akumulátory sú premenné, ktoré sa pridávajú k pridruženým operáciám. Existuje veľa použití pre akumulátory, ako sú počítadlá, sumy atď.

Názov akumulátora v kóde je viditeľný aj v používateľskom rozhraní Spark.
-
mapa
Funkcia Mapa pomáha pri opakovaní na každom riadku v RDD. Funkcia použitá v mape sa použije na každý prvok v RDD.
Napríklad v RDD (1, 2, 3, 4, 6), ak použijeme „rdd.map (x => x + 2)“, dostaneme výsledok ako (3, 4, 5, 6, 8).
-
Flatmap
Flatmap funguje podobne ako mapa, ale mapa vracia iba jeden prvok, zatiaľ čo flatmap môže vrátiť zoznam prvkov. Preto si rozdelenie viet na slová bude vyžadovať flatmap.
-
splynúť
Táto funkcia pomáha zabrániť zamiešaniu údajov. Toto sa aplikuje v existujúcom oddiele, takže sa zamieša menej údajov. Týmto spôsobom môžeme obmedziť použitie uzlov v klastri.
Tipy a triky na použitie iskrových príkazov
Nižšie sú uvedené rôzne tipy a triky príkazov Spark: -
- Začiatočníci Spark môžu používať Spark-shell. Pretože príkazy Spark sú postavené na Scale, je určite skvelé používať iskru shell Scala. K dispozícii je však aj pythonová iskričacia škrupina, takže aj to, čo môže človek použiť, je dobre oboznámený s pythónom.
- Spark shell má veľa možností na správu zdrojov klastra. Nižšie vám môže pomôcť príkaz Command:

- V programe Spark je obvyklá práca s dlhými súbormi údajov. Ale keď sa zlé vstupy nepovedú, veci sa pokazia. Vždy je vhodné zahodiť zlé riadky pomocou filtračnej funkcie Spark. Dobrý súbor vstupov bude skvelý krok.
- Spark si vyberie vlastný oddiel pre svoje dáta. Vždy je však dobré dbať na oddiely skôr, ako začnete pracovať. Vyskúšanie rôznych oddielov vám pomôže s paralelizáciou vašej práce.
Záver - príkazy iskier:
Príkaz Spark je revolučný a všestranný veľký dátový stroj, ktorý môže pracovať pre dávkové spracovanie, spracovanie v reálnom čase, ukladanie údajov do vyrovnávacej pamäte atď. Spark má bohatú sadu knižníc strojového učenia, ktoré umožňujú vedcom údajov a analytickým organizáciám budovať silné, interaktívne a rýchle aplikácie.
Odporúčané články
Toto bol sprievodca príkazmi Spark. Tu sme diskutovali základné aj pokročilé príkazy Spark a niektoré okamžité príkazy Spark. Viac informácií nájdete aj v nasledujúcom článku -
- Príkazy Adobe Photoshop
- Dôležité príkazy VBA
- Tableauove príkazy
- Cheat sheet SQL (Príkazy, Tipy a triky)
- Typy pripojení v programe Spark SQL (príklady)
- Súčasti iskier Prehľad a 6 najlepších komponentov