

Úvod do BFS algoritmu
Pre efektívny prístup k údajom a ich správu je možné ich uložiť a usporiadať do špeciálneho formátu známeho ako dátová štruktúra. Existuje veľa dátových štruktúr, ako sú stack, pole, prepojený zoznam, fronty, stromy a grafy atď. V lineárnych dátových štruktúrach, ako sú stack, pole, prepojený zoznam a fronta, sú údaje usporiadané v lineárnom poradí, zatiaľ čo v lineárne dátové štruktúry ako Stromy a Grafy, dáta nie sú usporiadané hierarchicky. Graf je nelineárna dátová štruktúra, ktorá má uzly a hrany. Uzly v grafe môžu byť tiež označované ako vrcholy, ktoré sú obmedzené počtom a hrany sú spojovacie čiary medzi akýmikoľvek dvoma uzlami.
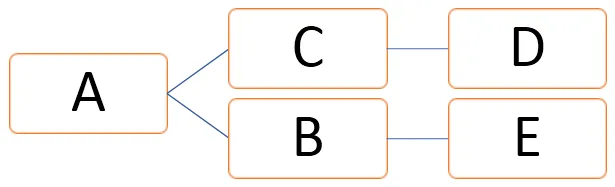
Vo vyššie uvedenom grafe môžu byť vrcholy znázornené ako V = (A, B, C, D, E) a hrany môžu byť definované ako
E = (AB, AC, CD, BE)
Čo je algoritmus BFS?
Všeobecne existujú dva algoritmy, ktoré sa používajú na prechod grafom. Sú to algoritmy BFS (Bththth First Search) a DFS (Depth First Search). Prechod grafu navštevuje presne jedenkrát každý vrchol alebo uzol a hranu v presne definovanom poradí. Je tiež dôležité sledovať vrcholy, ktoré boli navštívené, aby sa ten istý vrchol neprešiel dvakrát. V algoritme Breath First Search sa prechod začína z vybraného uzla alebo zdrojového uzla a prechod pokračuje cez uzly priamo pripojené k zdrojovému uzlu. Zjednodušene povedané, v algoritme BFS by sa najprv mal vodorovne posúvať a prechádzať aktuálna vrstva, po ktorej by sa malo vykonať presunutie na ďalšiu vrstvu.
Ako funguje algoritmus BFS?
Vezmime príklad z nižšie uvedeného grafu.
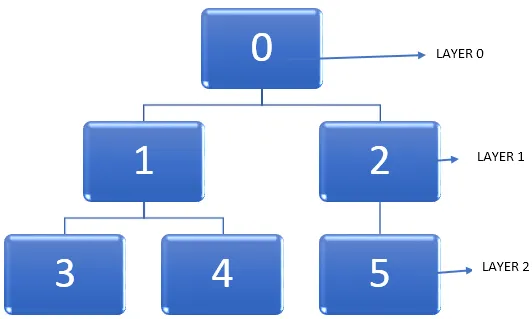
Dôležitou úlohou je nájsť najkratšiu cestu v grafe pri prechode uzlami. Keď prejdeme grafom, vrchol prejde z neobjaveného stavu do objaveného stavu a nakoniec sa úplne objaví. Je potrebné poznamenať, že je možné uviaznuť v určitom okamihu pri prechode grafom a uzlom je možné navštíviť dvakrát. Môžeme teda použiť metódu označovania uzlov potom, čo zmení stav neobjavenia na úplné odhalenie.
Na obrázku nižšie vidíme, že uzly môžu byť v grafoch označené, keď sa úplne objavia ich čiernym označením. Môžeme začať od zdrojového uzla a ako traverza prechádza každým uzlom, môžu byť označené, aby boli identifikované.
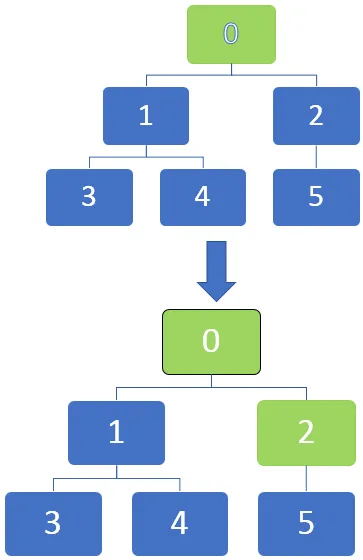
Prechod začína od vrcholu a potom prechádza k odchádzajúcim hranám. Keď hrana prejde na neobjavený vrchol, označí sa ako objavený. Keď však hrana prejde na úplne objavený alebo objavený vrchol, ignoruje sa.
V prípade smerovaného grafu sa každá hrana navštívi raz a v prípade nepriameho grafu sa navštívi dvakrát, tj raz pri návšteve každého uzla. O algoritme, ktorý sa má použiť, sa rozhodne na základe spôsobu uloženia zistených vrcholov. V algoritme BFS sa používa front, kde sa najskôr objaví najstarší vrchol a potom sa šíri cez vrstvy z počiatočného vrcholu.
Kroky sa vykonávajú pre algoritmus BFS
Nižšie uvedené kroky sa vykonávajú pre algoritmus BFS.
- V danom grafe začnime od vrcholu, tj vo vyššie uvedenom diagrame je uzol 0. Úroveň, v ktorej je tento vrchol prítomný, môže byť označená ako vrstva 0.
- Ďalším krokom je nájsť všetky ostatné vrcholy, ktoré susedia s východiskovým vrcholom, tj uzol 0 alebo sú z neho okamžite prístupné. Potom môžeme tieto susedné vrcholy označiť tak, aby boli prítomné vo vrstve 1.
- Je možné dospieť k rovnakému vrcholu kvôli slučke v grafe. Mali by sme teda cestovať iba do tých vrcholov, ktoré by mali byť v tej istej vrstve.
- Ďalej je označený rodičovský vrchol aktuálneho vrcholu, v ktorom sa nachádzame. To isté sa má vykonať pre všetky vrcholy vo vrstve 1.
- Ďalším krokom je nájdenie všetkých tých vrcholov, ktoré sú jedna hrana od všetkých vrcholov, ktoré sú vo vrstve 1. Táto nová sada vrcholov bude vo vrstve 2.
- Vyššie uvedený proces sa opakuje dovtedy, kým sa neprechádzajú všetky uzly.
Príklad:
Zoberme si príklad nižšie uvedeného grafu a pochopíme, ako funguje algoritmus BFS. Všeobecne sa v algoritme BFS fronta používa na frontu pri zaraďovaní do fronty počas ich prechádzania uzlami.
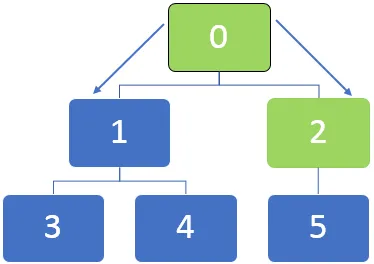
Vo vyššie uvedenom grafe je najprv potrebné navštíviť uzol 0 a tento uzol sa zaradiť do frontu pod frontu:

Po návšteve uzla 0 je susedný uzol 0, 1 a 2 zaradený do fronty. Frontu je možné znázorniť takto: 
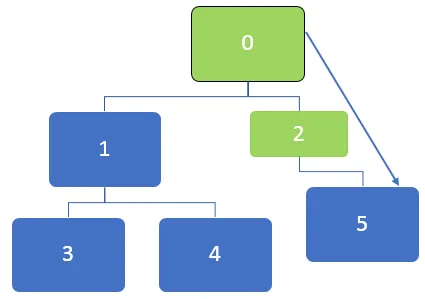
Potom bude navštívený prvý uzol vo fronte, ktorý je 2. Po návšteve uzla 2 je možné frontu znázorniť takto:

Po návšteve uzla 2 bude 5 zaradených do fronty a keďže neexistujú žiadne nenavštívené susedné uzly pre uzol 5, napriek tomu je 5 zaradených do fronty, ale nebude dvakrát navštívené.
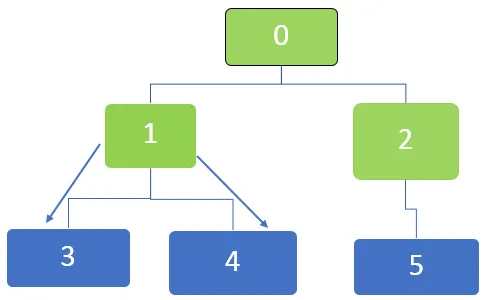
Ďalej je prvým uzlom vo fronte 1, ktorý sa navštívi. Susedné uzly 3 a 4 sú zaradené do fronty. Fronta je znázornená nižšie

Ďalej, prvý uzol vo fronte je 5 a pre tento uzol už nie sú žiadne nenavštívené susedné uzly. To isté platí pre uzly 3 a 4, pre ktoré už neexistujú žiadne ďalšie neviditeľné susedné uzly.
Prechádzajú teda všetky uzly a fronta sa nakoniec vyprázdni.

záver
Algoritmus vyhľadávania šírky má niekoľko vynikajúcich výhod, ktoré odporúčame. Jednou z mnohých aplikácií algoritmu BFS je výpočet najkratšej cesty. Používa sa tiež pri vytváraní sietí na nájdenie susedných uzlov a nachádza sa na stránkach sociálnych sietí, sieťovom vysielaní a zbere odpadu. Používatelia musia pochopiť požiadavku a štruktúru údajov, aby ju mohli používať pre lepší výkon.
Odporúčané články
Toto bol sprievodca algoritmom BFS. Tu diskutujeme koncepciu, prácu, kroky a príklad výkonu v algoritme BFS. Ak sa chcete dozvedieť viac, môžete si tiež prečítať naše ďalšie navrhované články -
- Čo je to chamtivý algoritmus?
- Algoritmus sledovania lúčov
- Algoritmus digitálneho podpisu
- Čo je to Java Hibernate?
- Kryptografia digitálneho podpisu
- BFS VS DFS 6 hlavných rozdielov s infografikami