
Úvod do životného cyklu údajov
Data Science Lifecycle sa točí okolo používania strojového učenia a iných analytických metód na vytváranie poznatkov a predpovedí z údajov, aby sa dosiahol obchodný cieľ. Celý proces zahŕňa niekoľko krokov, ako je čistenie údajov, príprava, modelovanie, hodnotenie modelu atď. Je to dlhý proces a jeho dokončenie môže trvať niekoľko mesiacov. Preto je veľmi dôležité mať všeobecnú štruktúru, ktorá sa musí dodržať pri každom probléme. Globálne uznávaná štruktúra v riešení akýchkoľvek analytických problémov sa nazýva medzisektorový štandardný proces pre ťažbu údajov alebo rámec CRISP-DM.
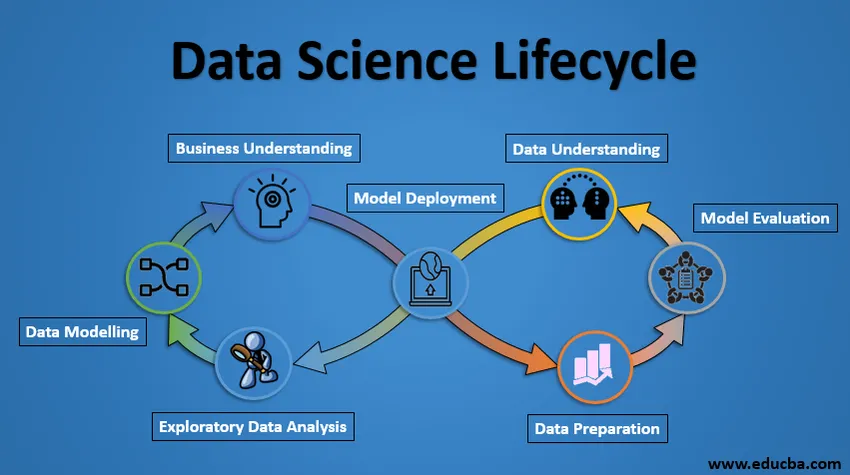
Životný cyklus dátovej vedy
Nižšie je uvedený projekt životného cyklu údajov.
1. Obchodné porozumenie
Celý cyklus sa točí okolo obchodného cieľa. Čo vyriešite, ak nemáte presný problém? Je nesmierne dôležité jasne pochopiť obchodný cieľ, pretože to bude váš konečný cieľ analýzy. Iba po správnom porozumení môžeme stanoviť konkrétny cieľ analýzy, ktorý je v súlade s obchodným cieľom. Musíte vedieť, či klient chce znížiť úverovú stratu, alebo či chce predpovedať cenu komodity atď.
2. Porozumenie údajom
Po obchodnom porozumení je ďalším krokom pochopenie údajov. Zahŕňa to zhromažďovanie všetkých dostupných údajov. Tu musíte úzko spolupracovať s obchodným tímom, pretože vedia, aké údaje sú k dispozícii, aké údaje by sa mohli použiť pre tento obchodný problém a ďalšie informácie. Tento krok zahŕňa opis údajov, ich štruktúru, relevantnosť, typ údajov. Preskúmajte údaje pomocou grafických grafov. V podstate získavanie akýchkoľvek informácií, ktoré môžete získať o údajoch, stačí ich preskúmať.
3. Príprava údajov
Ďalej prichádza fáza prípravy údajov. Patria sem kroky, ako je výber relevantných údajov, integrácia údajov zlúčením súborov údajov, ich čistenie, ošetrenie chýbajúcich hodnôt buď ich odstránením alebo imputáciou, spracovanie chybných údajov ich odstránením, tiež kontrola odlehlých údajov pomocou škatuľových grafov a ich spracovanie., Vytváranie nových údajov, odvodenie nových funkcií z existujúcich. Naformátujte údaje do požadovanej štruktúry, odstráňte nežiaduce stĺpce a prvky. Príprava údajov je časovo najnáročnejšia, ale pravdepodobne najdôležitejšia etapa celého životného cyklu. Váš model bude rovnako dobrý ako vaše údaje.
4. Analýza prieskumných údajov
Tento krok zahŕňa získanie predstavy o riešení a faktoroch, ktoré ho ovplyvňujú, pred vytvorením skutočného modelu. Distribúcia údajov v rámci rôznych premenných prvku sa skúma graficky pomocou stĺpcových grafov. Vzťahy medzi rôznymi znakmi sa zachytávajú prostredníctvom grafických znázornení, ako sú napríklad rozptylové grafy a tepelné mapy. Mnoho ďalších techník vizualizácie údajov sa vo veľkej miere používa na skúmanie každej funkcie jednotlivo a ich kombináciou s inými funkciami.
5. Modelovanie dát
Modelovanie údajov je jadrom analýzy údajov. Model berie pripravené dáta ako vstup a poskytuje požadovaný výstup. Tento krok zahŕňa výber vhodného typu modelu, či už ide o problém klasifikácie, alebo o regresný problém alebo problém zoskupovania. Po výbere rodiny modelov, medzi rôznymi algoritmami v tejto rodine, musíme starostlivo vybrať algoritmy, aby sme ich mohli implementovať a implementovať. Aby sme dosiahli požadovaný výkon, musíme vyladiť hyperparametre každého modelu. Musíme sa tiež uistiť, že existuje správna rovnováha medzi výkonom a zovšeobecnením. Nechceme, aby sa model učil údaje a na nových údajoch mal slabý výkon.
6. Hodnotenie modelu
Tu je model vyhodnotený na kontrolu, či je pripravený na nasadenie. Model je testovaný na neviditeľných údajoch, hodnotený na starostlivo premyslenom súbore hodnotiacich metrík. Musíme sa tiež uistiť, že model zodpovedá skutočnosti. Ak pri hodnotení nedosiahneme uspokojivý výsledok, musíme celý proces modelovania znova opakovať, kým sa nedosiahne požadovaná úroveň metrík. Akékoľvek riešenie v oblasti vedy o údajoch, model strojového učenia, rovnako ako človek, by sa malo vyvíjať, malo by byť schopné vylepšiť sa pomocou nových údajov a prispôsobiť sa novej metrike hodnotenia. Môžeme zostaviť niekoľko modelov pre určitý jav, ale mnoho z nich môže byť nedokonalých. Hodnotenie modelu nám pomáha pri výbere a zostavení dokonalého modelu.
7. Nasadenie modelu
Model po dôkladnom vyhodnotení je nakoniec nasadený v požadovanom formáte a kanáli. Toto je posledný krok v životnom cykle vedy o údajoch. Každý krok v životnom cykle vedy o údajoch, ktorý je uvedený vyššie, by sa mal starostlivo spracovať. Ak je ktorýkoľvek krok vykonaný nesprávne, bude to mať vplyv na ďalší krok a celé úsilie ide do odpadu. Napríklad, ak sa údaje nezhromažďujú správne, stratíte informácie a nebudete stavať dokonalý model. Ak údaje nie sú správne vyčistené, model nebude fungovať. Ak model nebude správne vyhodnotený, v reálnom svete zlyhá. Od obchodného porozumenia po nasadenie modelu by sa mal každému kroku venovať náležitá pozornosť, čas a úsilie.
Odporúčané články
Toto je sprievodca životným cyklom Data Science. Tu diskutujeme prehľad životného cyklu údajov a kroky, ktoré tvoria životný cyklus údajov. Viac informácií nájdete aj v našich súvisiacich článkoch -
- Úvod do algoritmov vedy o údajoch
- Data Science vs Softvérové inžinierstvo Top 8 užitočných porovnaní
- Rozdielne typy metód vedy o údajoch
- Zručnosti v oblasti dát s typmi