
Rozdiel medzi BFS VS DFS
Vyhľadávanie podľa šírky pásma (BFS) a hĺbkového prvého vyhľadávania (DFS) sú dva dôležité algoritmy používané na vyhľadávanie. Prvé vyhľadávanie šírky začína svoje vyhľadávanie od prvého uzla a potom sa pohybuje po úrovniach, ktoré sú bližšie ku koreňovému uzlu, zatiaľ čo algoritmus hĺbkového prvého vyhľadávania začína prvým uzlom a potom dokončí svoju cestu k koncovému uzlu príslušnej cesty. Obidva algoritmy prechádzajú cez každý uzol počas vyhľadávania. Pre tieto dva algoritmy sú napísané rôzne kódy na vykonávanie procesu prechádzania. Sú tiež považované za dôležité vyhľadávacie algoritmy v umelej inteligencii.
V tejto téme sa dozvieme viac o BFS VS DFS.
Ako fungujú BFS a DFS?
Pracovný mechanizmus oboch algoritmov je vysvetlený nižšie s príkladmi. Ak chcete lepšie porozumieť použitému prístupu, obráťte sa na ne.
Príklad šírky šírky
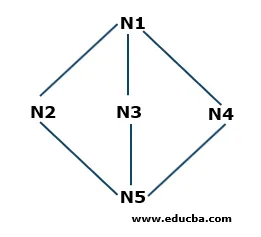
- Krok 1: N1 je koreňový uzol, takže začne odtiaľto. N1 je spojený s tromi uzlami N2, N3 a N4. Všetky tri uzly ešte nie sú navštívené. Začneme teda od N2 a uložíme ich do frontu. Takže front s názvom Q obsahuje iba N2.
Q: N2
- Krok 2: Ďalším uzlom, ktorý je pripojený k N1, je N3. Pretože sme prešli alebo navštívili uzol, uložíme ho do frontu. Aktualizovaný front je teda
Q: N3, N2
- Krok 3: Ďalší uzol, ktorý je pripojený ku koreňovému uzlu, je N4. Uložíme ich do frontu.
Q: N4, N3, N2
- Krok 4: Všetky uzly, ktoré sú pripojené k N1, sú uložené vo fronte. Teraz odstránime N2 z frontu podľa princípu First in First Out (FIFO) a nájdeme uzly, ktoré sú pripojené k N2, tj N5. N5 nie je navštívený raz, takže ho uložíme do frontu.
Q: N5, N4, N3
- Krok 5: Navštívia sa všetky vrcholy, takže stále odstraňujeme uzly z frontu, až kým nebudú prázdne.
Príklad prvého hĺbky vyhľadávania
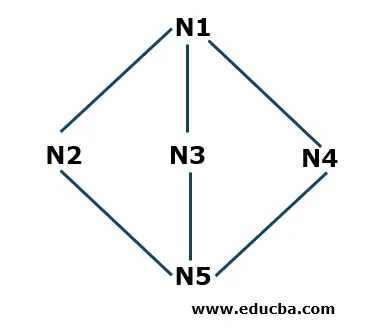
- Krok 1: Začneme N1 ako východiskovým uzlom a uložíme ho do zásobníka S. N1 je spojený s tromi susednými uzlami N2, N3 a N4. Počnúc N2 (môžete začať abecedne alebo číselne), vložíme to do zásobníka.
S: N2 (hore), N1
- Krok 2: Teraz sú susednými uzlami N2 N1 a N5. Pretože N1 je už v zásobníku, to znamená, že je navštívený, preto vezmeme N5 a vložíme ho do zásobníka S.
S: N5 (hore), N2, N1
- Krok 3: Teraz sú susednými uzlami N5 N3 a N4. Začneme N3 a vložíme ho do zásobníka.
S: N3 (hore), N5, N2, N1
Teraz je N3 pripojený k N5 a N1, ktoré sú už v zásobníku, to znamená, že sú navštívené, takže odstránime N3 zo zásobníka podľa princípu Last in First Out (LIFO).
S: N5 (hore), N2, N1
- Krok 4: Teraz vložíme posledný uzol, v ktorom sme sa v celom prejazde N4 nestretli, a umiestnime ho do stohu.
S: N4 (hore), N5, N2, N1
- Krok 5: Teraz nie sme vynechaní s inými uzlami, takže v zásobníku skontrolujeme, či sú v ňom prítomné nejaké uzly, ktoré nie sú navštívené. Ak sú navštívené všetky pripojené uzly, odstránime uzly prítomné v zásobníku. Napríklad N4 nemá žiadne spojovacie uzly, ktoré sme nekontrolovali, takže ho zo zásobníka odstránime. Podobne môžeme skontrolovať ďalšie uzly. Algoritmus sa zastaví, keď je zásobník prázdny.
Porovnanie medzi hlavami medzi BFS VS DFS (infografika)
Nižšie je uvedených 6 najlepších rozdielov medzi BFS VS DFS
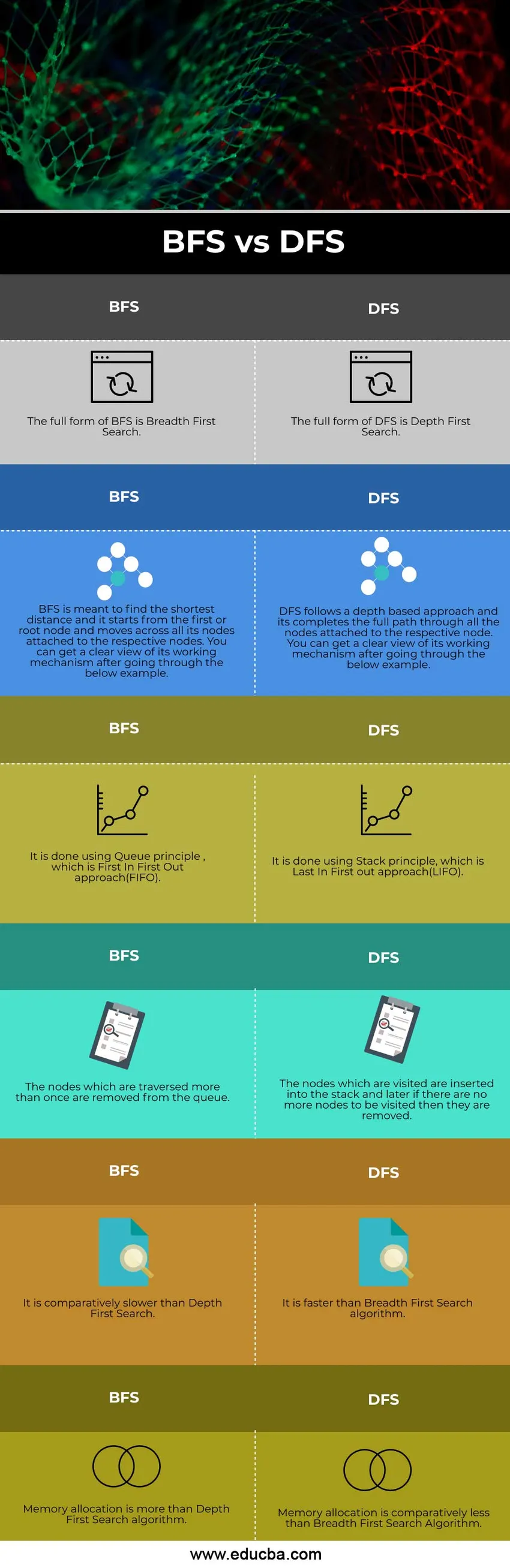
Kľúčové rozdiely medzi BFS a DFS
Poďme diskutovať o niektorých hlavných kľúčových rozdieloch medzi BFS a DFS
- Vyhľadávanie podľa šírky (BFS) sa začína od koreňového uzla a navštevuje všetky príslušné uzly, ktoré sú k nemu pripojené, zatiaľ čo DFS sa začína od koreňového uzla a dokončí úplnú cestu pripojenú k uzlu.
- BFS sa riadi prístupom Queue, zatiaľ čo DFS sa riadi prístupom Stack.
- Prístup používaný v BFS je optimálny, zatiaľ čo postup použitý v DFS nie je optimálny.
- Ak je naším cieľom nájsť najkratšiu cestu ako BFS, uprednostňuje sa pred DFS.
Porovnávacia tabuľka BFS a DFS
Poďme diskutovať o najlepšom porovnaní medzi BFS a DFS
| BFS | DFS |
| Úplnou formou BFS je vyhľadávanie podľa šírky. | Úplnou formou DFS je hĺbkové prvé vyhľadávanie |
| Účelom BFS je nájsť najkratšiu vzdialenosť a začína od prvého alebo koreňového uzla a pohybuje sa cez všetky svoje uzly pripojené k príslušným uzlom. Po prečítaní nižšie uvedeného príkladu získate jasný prehľad o jeho pracovnom mechanizme. | DFS postupuje na základe hĺbky a dokončí úplnú cestu cez všetky uzly pripojené k príslušnému uzlu. Po prečítaní nižšie uvedeného príkladu získate jasný prehľad o jeho pracovnom mechanizme. |
| Uskutočňuje sa to pomocou princípu Queue, ktorý predstavuje prístup FIFO (First In First Out). | Robí sa to pomocou princípu Stack, čo je prístup Last In First out (LIFO). |
| Uzly, ktoré prechádzajú viackrát, sa odstránia z frontu. | Navštívené uzly sa vložia do zásobníka a neskôr, ak už nie sú k dispozícii žiadne ďalšie uzly, odstránia sa. |
| Je pomerne pomalšia ako hĺbka prvého vyhľadávania. | Je to rýchlejšie ako algoritmus vyhľadávania podľa šírky prvého. |
| Priradenie pamäte je viac ako algoritmus hĺbkového prvého vyhľadávania. | Priradenie pamäte je pomerne menšie ako algoritmus rozšíreného vyhľadávania |
záver
Existuje mnoho aplikácií, v ktorých sa vyššie uvedené algoritmy používajú ako strojové učenie alebo na nájdenie riešení týkajúcich sa umelej inteligencie atď. Používajú sa hlavne v grafoch na zistenie, či je alebo nie je bipartitný, na detekciu cyklov alebo komponentov, ktoré sú spojené. Považujú sa tiež za dôležité algoritmy pri hľadaní cesty alebo pri hľadaní najmenšej vzdialenosti. V závislosti od požiadaviek podnikania môžeme použiť dva algoritmy. Šírka-prvé vyhľadávanie sa však považuje za optimálny spôsob, a nie za algoritmus hĺbkového prvého vyhľadávania.
Odporúčané články
Toto je sprievodca BFS VS DFS. Tu diskutujeme kľúčové rozdiely BFS VS DFS s infografikou a porovnávacou tabuľkou. Ďalšie informácie nájdete aj v nasledujúcich článkoch -
- Algoritmus BFS
- TeraData vs Oracle
- Big Data vs Data Warehouse
- Big Data vs Apache Hadoop: Najlepšie porovnania 4, ktoré sa musíte naučiť