
Úvod do modelov strojového učenia
Prehľad rôznych modelov strojového učenia používaných v praxi. Podľa definície je model strojového učenia matematickou konfiguráciou získanou po použití konkrétnych metodík strojového učenia. Pri použití rozsiahlej škály rozhraní API je dnes výroba modelu strojového učenia v podstate priamočiara s menším počtom kódov. Skutočná zručnosť odborníka na aplikovanú vedu v oblasti údajov spočíva v výbere správneho modelu založeného na vyhlásení problému a krížovej validácii namiesto náhodného hádzania údajov do efektných algoritmov. V tomto článku budeme diskutovať o rôznych modeloch strojového učenia a o tom, ako ich efektívne používať na základe typu problémov, ktoré riešia.
Typy modelov strojového učenia
Na základe typu úloh môžeme klasifikovať modely strojového učenia do nasledujúcich typov:
- Klasifikačné modely
- Regresné modely
- clustering
- Zníženie rozmerov
- Hlboké učenie atď.
1) Klasifikácia
Pokiaľ ide o strojové učenie, klasifikácia je úlohou predpovedať typ alebo triedu objektu v rámci obmedzeného počtu možností. Výstupná premenná pre klasifikáciu je vždy kategorická premenná. Napríklad, predpovedanie e-mailu je spam alebo nie, je štandardnou úlohou binárnej klasifikácie. Pozrime sa na niektoré dôležité modely problémov klasifikácie.
- Algoritmus K-Nearest Neighbors - jednoduchý, ale výpočetne vyčerpávajúci.
- Naive Bayes - Na základe Bayesovej vety.
- Logistická regresia - lineárny model pre binárnu klasifikáciu.
- SVM - dá sa použiť na binárne / viacstupňové klasifikácie.
- Rozhodovací strom - Klasifikátor na báze „ ak je iný “, robustnejší pre odľahlé hodnoty.
- Zostavy - Kombinácia viacerých modelov strojového učenia sa spája, aby sa dosiahli lepšie výsledky.
2) Regresia
V stroji je regresia učenia súbor problémov, v ktorých výstupná premenná môže nadobúdať kontinuálne hodnoty. Predikcia ceny leteckej spoločnosti sa môže napríklad považovať za štandardnú regresnú úlohu. Pozrime sa na niektoré dôležité regresné modely používané v praxi.
- Lineárna regresia - najjednoduchší základný model pre regresnú úlohu, funguje dobre iba vtedy, keď sú údaje lineárne oddeliteľné a ak je prítomná veľmi nízka alebo žiadna multicollinearita.
- Lasová regresia - lineárna regresia s regularizáciou L2.
- Ridge Regression - Lineárna regresia s regularizáciou L1.
- Regresia SVM
- Regresia stromu rozhodnutí atď.
3) Zhlukovanie
Jednoducho povedané, zoskupovanie je úlohou zoskupovania podobných objektov. Modely strojového učenia pomáhajú automaticky identifikovať podobné objekty bez manuálneho zásahu. Bez homogénnych údajov nemôžeme zostaviť efektívne dohliadané modely strojového učenia (modely, ktoré je potrebné trénovať pomocou ručne kurovaných alebo označených údajov). Zhlukovanie nám pomáha dosiahnuť to inteligentnejšie. Nasleduje niekoľko bežne používaných klastrových modelov:
- K znamená - Jednoduché, ale trpí veľkým rozptylom.
- K znamená ++ - Modifikovaná verzia K znamená.
- K medoidy.
- Aglomeračné klastrovanie - hierarchický klastrovací model.
- DBSCAN - algoritmus klastrovania založený na hustote atď.
4) Zníženie rozmerov
Dimenzionalita je počet prediktorových premenných používaných na predpovedanie nezávislej premennej alebo cieľa. V reálnom svete je počet premenných príliš vysoký. Príliš veľa premenných prináša modely prekliatie. V praxi medzi týmito veľkými počtami premenných nie všetky premenné prispievajú rovnako k cieľu av mnohých prípadoch môžeme skutočne zachovať odchýlky s menším počtom premenných. Vymenujme niektoré bežne používané modely na zníženie rozmerov.
- PCA - Vytvára menšie množstvo nových premenných z veľkého počtu prediktorov. Nové premenné sú na sebe nezávislé, ale menej interpretovateľné.
- TSNE - Poskytuje vkladanie trojrozmerných údajových bodov do nižšej dimenzie.
- SVD - Singular value decomposition sa používa na rozklad matice na menšie časti, aby sa dosiahol efektívny výpočet.
5) Hlboké učenie
Hlboké vzdelávanie je podmnožinou strojového učenia, ktoré sa zaoberá neurónovými sieťami. Na základe architektúry neurónových sietí si vymenujme dôležité hlboké učebné modely:
- Viacvrstvový perceptrón
- Neurónové siete konvolúcie
- Opakujúce sa neurónové siete
- Boltzmann stroj
- Autoenkodéry atď.
Ktorý model je najlepší?
Vyššie sme vzali nápady na veľa modelov strojového vzdelávania. Teraz nás napadne očividná otázka „Ktorý z nich je najlepší model?“ Závisí to od daného problému a ďalších súvisiacich atribútov, ako sú odľahlé hodnoty, objem dostupných údajov, kvalita údajov, konštrukčné riešenie atď. V praxi je vždy vhodnejšie začať s najjednoduchším modelom, ktorý sa dá na problém použiť, a zvýšiť zložitosť. postupne správnym nastavením parametrov a krížovou validáciou. Vo svete údajov existuje príslovie - „Krížová validácia je dôveryhodnejšia ako znalosť domény“.
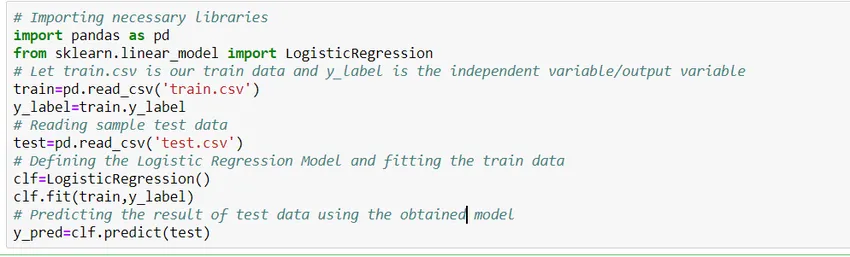
Ako zostaviť model?
Pozrime sa, ako zostaviť jednoduchý logistický regresný model pomocou knižnice Scikit Learn python. Pre jednoduchosť predpokladáme, že problémom je štandardný klasifikačný model a „train.csv“ je vlak a „test.csv“ sú údaje o vlaku a teste.
záver
V tomto článku sme diskutovali o dôležitých modeloch strojového učenia, ktoré sa používajú na praktické účely, ao tom, ako v Pythone vytvoriť jednoduchý model strojového učenia. Výber správneho modelu pre konkrétny prípad použitia je veľmi dôležitý na získanie správneho výsledku úlohy strojového učenia. Na porovnanie výkonnosti medzi rôznymi modelmi sú definované metriky hodnotenia alebo KPI pre konkrétne obchodné problémy a po použití štatistickej kontroly výkonnosti sa vyberie najlepší model pre výrobu.
Odporúčané články
Toto je príručka pre modely strojového učenia. Tu diskutujeme o 5 najdôležitejších modeloch strojového učenia s ich definíciou. Viac informácií nájdete aj v ďalších navrhovaných článkoch -
- Metódy strojového učenia
- Druhy strojového učenia
- Algoritmy strojového učenia
- Čo je to strojové učenie?
- Hyperparameter Machine Learning
- KPI v Power BI
- Hierarchický klastrovací algoritmus
- Hierarchické zoskupovanie Aglomeračné a deliace sa zoskupovanie