

Úvod do služby Pripojiť sa k Úlu
Pripojiť sa k mape je funkcia používaná v dotazoch Hive na zvýšenie jej efektívnosti z hľadiska rýchlosti. Pripojiť je stav, ktorý sa používa na kombináciu údajov z 2 tabuliek. Keď teda vykonáme normálne pripojenie, úloha sa odošle do úlohy Map-Reduce, ktorá rozdelí hlavnú úlohu do dvoch fáz - „Mapová fáza“ a „Redukčná fáza“. Fáza Map interpretuje vstupné dáta a vracia výstup do redukčnej fázy vo forme párov kľúč - hodnota. Nasleduje etapa miešania, v ktorej sú triedené a kombinované. Reduktor vezme túto zoradenú hodnotu a dokončí úlohu spojenia.
Tabuľku je možné načítať do pamäte úplne v mapovači a bez toho, aby ste museli používať proces Map / Reducer. Číta dáta z menšej tabuľky a ukladá ich do hašovacej tabuľky v pamäti a potom ju serializuje do hashového pamäťového súboru, čím sa podstatne skracuje čas. Známe je aj pod názvom Map Side Join in Hive. V zásade ide o vykonanie spojení medzi 2 tabuľkami iba pomocou fázy Map a preskočením fázy Reduce. Ak vo vašich dotazoch pravidelne používajú malé tabuľky, môže dôjsť k časovému skráteniu výpočtu vašich dopytov.
Syntax pre Map Pripojte sa k Úlu
Ak chceme vykonať dotaz na spojenie pomocou map-join, musíme do príkazu zadať kľúčové slovo „/ * + MAPJOIN (b) * /“, ako je uvedené nižšie:
>SELECT /*+ MAPJOIN(c) */ * FROM tablename1 t1 JOIN tablename2 t2 ON (t1.emp_id = t2.emp_id);
V tomto príklade musíme vytvoriť 2 tabuľky s názvami tablename1 a tablename2, ktoré majú 2 stĺpce: emp_id a emp_name. Jeden by mal byť väčší a druhý menší.
Pred spustením dotazu musíme nastaviť nasledujúcu vlastnosť na true:
hive.auto.convert.join=true
Dotaz na spojenie pre pripojenie k mape je napísaný ako vyššie a výsledok, ktorý dostaneme, je:
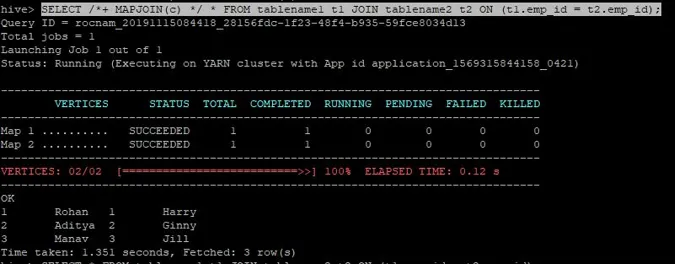
Dopyt bol dokončený za 1, 351 sekundy.
Príklady prihlásenia sa do úľa
Nižšie sú uvedené nasledujúce príklady
1. Príklad spojenia s mapou
V tomto príklade vytvorme 2 tabuľky s názvom table1 a table2 so 100 a 200 záznamami. Na vykonanie tohto príkazu si môžete pozrieť nasledujúci príkaz a snímky obrazovky:
>CREATE TABLE IF NOT EXISTS table1 ( emp_id int, emp_name String, email_id String, gender String, ip_address String) row format delimited fields terminated BY ', ' tblproperties("skip.header.line.count"="1");
>CREATE TABLE IF NOT EXISTS table2 ( emp_id int, emp_name String) row format delimited fields terminated BY ', ' tblproperties("skip.header.line.count"="1");

Teraz načítame záznamy do oboch tabuliek pomocou príkazov uvedených nižšie:
>load data local inpath '/relativePath/data1.csv' into table table1;
>load data local inpath '/relativePath/data2.csv' into table table2;
Vykonajme na svojich identifikátoroch bežný dotaz na pripojenie mapy, ako je to znázornené nižšie, a overte si čas, ktorý je potrebný:
>SELECT /*+ MAPJOIN(table2) */ table1.emp_name, table1.emp_id, table2.emp_id FROM table1 JOIN table2 ON table1.emp_name = table2.emp_name;
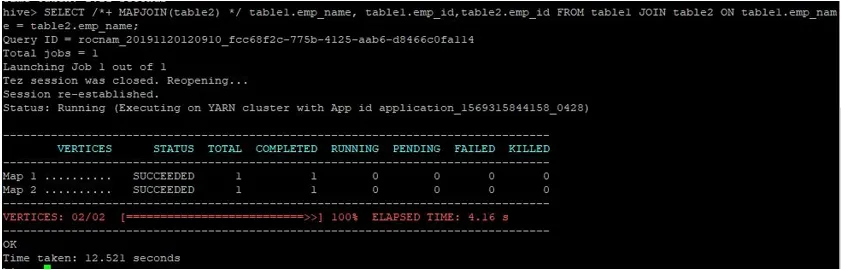
Ako vidíme, normálny dotaz na spojenie s mapou trval 12 521 sekúnd.
2. Príklad pripojenia k bucket-mape
Poďme teraz použiť Bucket-map pripojiť sa spustiť rovnaké. Existuje niekoľko obmedzení, ktoré je potrebné dodržiavať pri skladaní:
- Vedrá môžu byť navzájom spojené iba vtedy, ak sú celkové vedrá ľubovoľnej tabuľky násobkom počtu vedier v druhej tabuľke.
- Na vykonanie bucketingu musia mať tabuľky v dolnej doske. Preto vytvorme to isté.
Nasledujú príkazy, ktoré sa používajú na vytvorenie bucketovaných tabuliek tabuľky1 a tabuľky2:
>>CREATE TABLE IF NOT EXISTS table1_buk (emp_id int, emp_name String, email_id String, gender String, ip_address String) clustered by(emp_name) into 4 buckets row format delimited fields terminated BY ', ';
>CREATE TABLE IF NOT EXISTS table2_buk ( emp_id int, emp_name String) clustered by(emp_name) into 8 buckets row format delimited fields terminated BY ', ' ;

Rovnaké záznamy z tabuľky1 vložíme aj do týchto tabliet s bucketami:
>insert into table1_buk select * from table1;
>insert into table2_buk select * from table2;
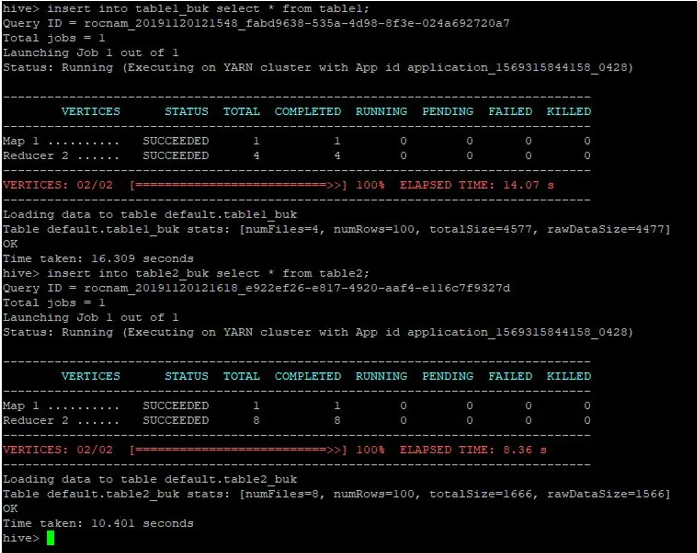
Teraz, keď máme 2 tabuľky s bucketami, urobme na nich spojenú mapu vedier. Prvá tabuľka má 4 vedrá, zatiaľ čo druhá tabuľka má 8 vedier vytvorených v rovnakom stĺpci.
Aby dotaz na spojku s mapou fungoval, mali by sme v podregistri nastaviť vlastnosť nižšie na true:
set hive.optimize.bucketmapjoin = true
>SELECT /*+ MAPJOIN(table2_buk) */ table1_buk.emp_name, table1_buk.emp_id, table2_buk.emp_id FROM table1_buk JOIN table2_buk ON table1_buk.emp_name = table2_buk.emp_name ;
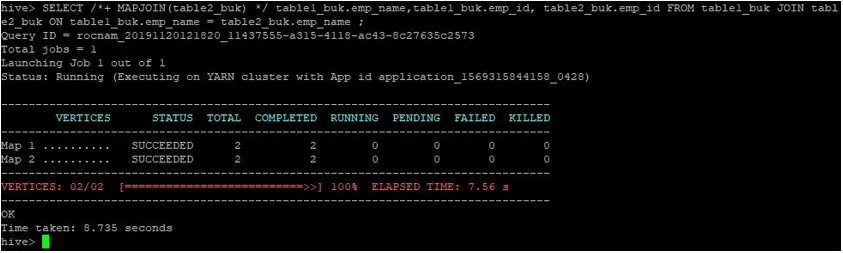
Ako vidíme, dotaz bol dokončený za 8, 735 sekúnd, čo je rýchlejšie ako normálne pripojenie mapy.
3. Zoradiť príklad spojenia zlúčiť spojenú mapu (SMB)
SMB sa môže vykonávať na bucketovaných tabuľkách, ktoré majú rovnaký počet vedier, a ak je potrebné tabuľky triediť a bucketed na spojených stĺpcoch. Úroveň Mapper sa k týmto vedrám primerane pripája.
Rovnako ako v prípade Bucket-map join, existujú 4 vedrá pre tabuľku1 a 8 vedier pre tabuľku2. V tomto príklade vytvoríme ďalšiu tabuľku so 4 vedierkami.
Ak chcete spustiť dotaz SMB, musíme nastaviť nasledujúce vlastnosti úľa, ako je uvedené nižšie:
Hive.input.format = org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;
hive.optimize.bucketmapjoin = true;
hive.optimize.bucketmapjoin.sortedmerge = true;
Na vykonanie spojenia SMB je potrebné údaje zoradiť podľa stĺpcov spojenia. Z tohto dôvodu prepíšeme údaje v tabuľke 1 bucketed, ako je uvedené nižšie:
>insert overwrite table table1_buk select * from table1 sort by emp_name;
Údaje sú teraz zoradené, čo je možné vidieť na nasledujúcom obrázku:
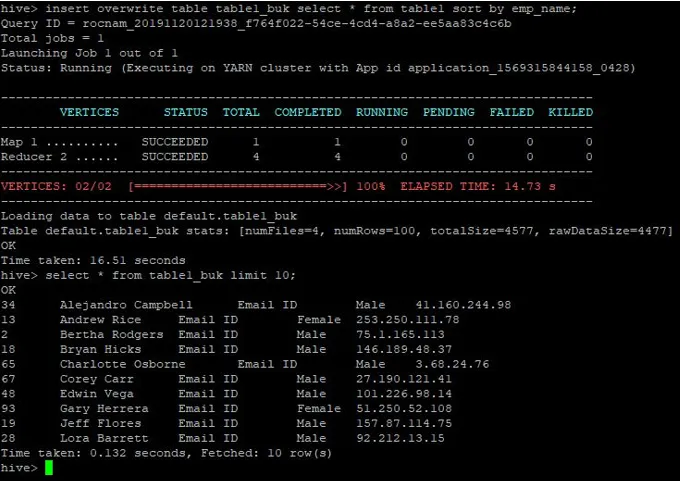
Ďalej prepíšeme údaje v tabu kovej tabuľke 2:
>insert overwrite table table2_buk select * from table2 sort by emp_name;

Vykonajme spojenie pre vyššie 2 tabuľky nasledovne:
>SELECT /*+ MAPJOIN(table2_buk) */ table1_buk.emp_name, table1_buk.emp_id, table2_buk.emp_id FROM table1_buk JOIN table2_buk ON table1_buk.emp_name = table2_buk.emp_name ;
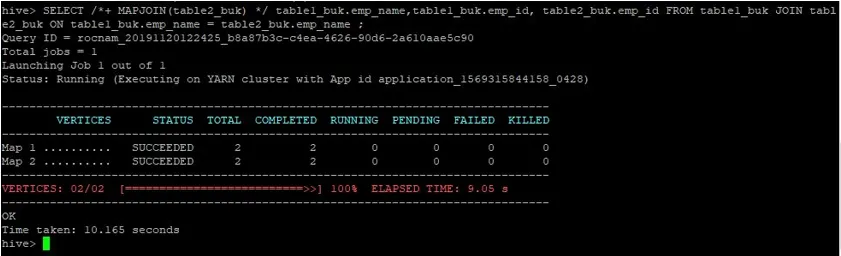
Vidíme, že dotaz trval 10, 165 sekúnd, čo je opäť lepšie ako normálne pripojenie mapy.
Vytvorme teraz ďalšiu tabuľku pre tabuľku2 so 4 vedierami a rovnakými údajmi zoradenými podľa emp_name.
>CREATE TABLE IF NOT EXISTS table2_buk1 (emp_id int, emp_name String) clustered by(emp_name) into 4 buckets row format delimited fields terminated BY ', ' ;
>insert overwrite table table2_buk1 select * from table2 sort by emp_name;
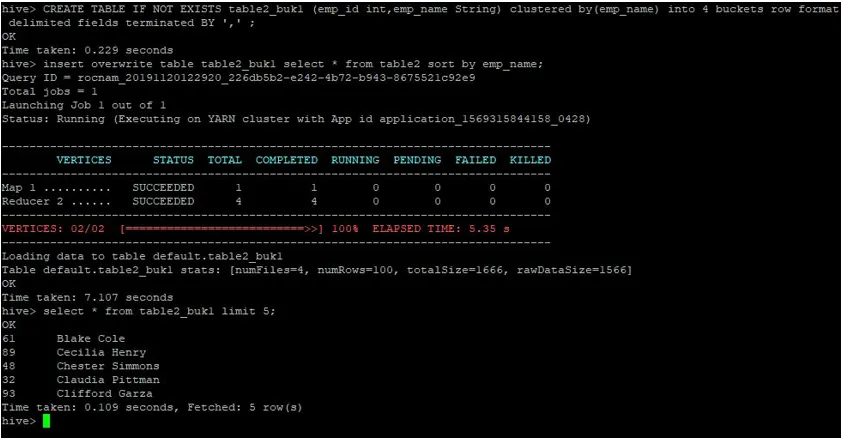
Vzhľadom na to, že teraz máme obe tabuľky so 4 vedierkami, vykonajte znova dotaz na pripojenie.
>SELECT /*+ MAPJOIN(table2_buk1) */table1_buk.emp_name, table1_buk.emp_id, table2_buk1.emp_id FROM table1_buk JOIN table2_buk1 ON table1_buk.emp_name = table2_buk1.emp_name ;
Dopyt trval opäť 8, 81 sekundy rýchlejšie ako normálny dotaz na pripojenie mapy.
výhody
- Map join znižuje čas potrebný na triedenie a zlučovanie procesov prebiehajúcich v náhodnom poradí a znižuje fázy a tým minimalizuje aj náklady.
- Zvyšuje výkonnosť úlohy.
obmedzenia
- Rovnaká tabuľka / alias sa nemôže použiť na spojenie rôznych stĺpcov v rovnakom dotaze.
- Dotaz na spojenie mapy nemôže prevádzať úplné vonkajšie spojenia na spojenia na strane mapy.
- Pripojenie mapy je možné vykonať iba vtedy, keď je jedna z tabuliek dostatočne malá, aby sa mohla zmestiť do pamäte. Preto nie je možné vykonať tam, kde sú údaje tabuľky obrovské.
- Ľavé spojenie je možné vykonať na mape iba vtedy, keď je správna veľkosť tabuľky malá.
- Pravé spojenie je možné vykonať na mape iba vtedy, keď je veľkosť ľavej tabuľky malá.
záver
Pokúsili sme sa zahrnúť čo najlepšie body Map Join in Hive. Ako sme videli vyššie, spojenie na strane mapy funguje najlepšie, keď jedna tabuľka obsahuje menej údajov, takže práca sa rýchlo dokončí. Čas potrebný na zobrazenie dopytov závisí od veľkosti súboru údajov, preto je tu uvedený čas len na analýzu. Pripojenie k mape sa dá ľahko implementovať v aplikáciách v reálnom čase, pretože máme obrovské množstvo údajov, čo pomáha znižovať sieťový I / O prenos.
Odporúčané články
Toto je sprievodca, ktorý sa pripojí k službe Hive. Tu diskutujeme o príkladoch funkcie Pripojiť sa k Úlu spolu s výhodami a obmedzeniami. Viac informácií nájdete aj v nasledujúcom článku -
- Pripojí sa v Úli
- Vstavané funkcie Úľa
- Čo je Úľ?
- Príkazy úľa