
Definícia stredného algoritmu posunu
Algoritmus priemerného posunu spadá pod učenie bez dozoru, ktoré je kategorizované ako algoritmus zoskupovania. Ideológia algoritmu Mean Shift spočíva v tom, že iteratívne prideľuje dátovým bodom klastrom posunutím smerom k bodu, ktorý má bod s najvyššou hustotou (režim). Logika priemerného posunu je založená na koncepcii odhadu hustoty jadra označovaného ako KDE.
Klastrovanie stredného algoritmu posunu
Fukunaga a Hostetler bez dozoru, ktorá nájde zhluky:
- Stredný posun je známy aj ako algoritmus na vyhľadávanie režimu, ktorý priraďuje dátové body klastrom tak, že posúva dátové body smerom k oblasti s vysokou hustotou. Najvyššia hustota dátových bodov sa nazýva model v regióne. Algoritmus stredného posunu má aplikácie široko používané v oblasti počítačového videnia a segmentácie obrazu.
- KDE je metóda odhadu distribúcie údajových bodov. Funguje to umiestnením jadra do každého údajového bodu. Matematicky je jadro váhová funkcia, ktorá bude aplikovať váhy pre jednotlivé dátové body. Pridanie všetkých jednotlivých jadier generuje pravdepodobnosť.
Funkcia jadra je povinná splniť nasledujúce podmienky:
- Prvou požiadavkou je zabezpečiť, aby bol odhad hustoty jadra normalizovaný.
- Druhou požiadavkou je, aby KDE bola dobre spojená so symetriou priestoru.
Dve populárne funkcie jadra
Nižšie sú uvedené dve populárne funkcie jadra:
- Ploché jadro
- Gaussovské jadro
- Na základe použitého jadra sa výsledná hustota mení. Ak nie je uvedený žiadny parameter jadra, štandardne sa vyvolá Gaussovo jadro. KDE využíva koncepciu funkcie hustoty pravdepodobnosti, ktorá pomáha nájsť lokálne maximá distribúcie údajov. Algoritmus funguje tak, že sa dátové body navzájom priťahujú, čo umožňuje dátovým bodom smerovať do oblasti s vysokou hustotou.
- Dátové body, ktoré sa snažia zbližovať smerom k miestnym maximám, budú z rovnakej skupiny klastrov. Na rozdiel od klastrovacieho algoritmu K-Means výstup algoritmu Mean Shift nezávisí od predpokladov na tvare dátového bodu a počte zhlukov. Počet zhlukov bude určený algoritmom s ohľadom na údaje.
- Aby sme mohli implementovať algoritmus Mean Shift, využívame balík python SKlearn.
Implementácia algoritmu stredného posunu
Nižšie je uvedená implementácia algoritmu:
Príklad č. 1
Na základe Sklearn výučby pre stredný algoritmus zoskupovania posunu. Prvý úryvok implementuje algoritmus stredného posunu, aby našiel zhluky dvojrozmernej sady údajov. Balíky použité na implementáciu stredného algoritmu posunu.
kód:
fromcluster importMeanShift, estimate_bandwidth
from sklearn.datasets.samples_generator import make_blobs as mb
importpyplot as plt
fromitertools import cycle as cy
Jednou z kľúčových vecí, ktorú treba poznamenať, je to, že budeme používať knižnicu make_blobs spoločnosti sklearn na generovanie dátových bodov sústredených na 3 miestach. Aby bolo možné aplikovať algoritmus stredného posunu na vygenerované body, musíme nastaviť šírku pásma, ktorá predstavuje interakciu medzi dĺžkou. Knižnica spoločnosti Sklearn má zabudované funkcie na odhadovanie šírky pásma.
kód:
#Sample data points
cen = ((1, .75), (-.75, -1), (1, -1)) x_train, _ = mb(n_samples=10000, centers= cen, cluster_std=0.6)
# Bandwidth estimation using in-built function
est_bandwidth = estimate_bandwidth(x_train, quantile=.1,
n_samples=500)
mean_shift = MeanShift(bandwidth= est_bandwidth, bin_seeding=True)
fit(x_train)
ms_labels = mean_shift.labels_
c_centers = ms_labels.cluster_centers_
n_clusters_ = ms_labels.max()+1
# Plot result
figure(1)
clf()
colors = cy('bgrcmykbgrcmykbgrcmykbgrcmyk')
fori, each inzip(range(n_clusters_), colors):
my_members = labels == i
cluster_center = c_centers(k) plot(x_train(my_members, 0), x_train(my_members, 1), each + '.')
plot(cluster_center(0), cluster_center(1),
'o', markerfacecolor=each,
markeredgecolor='k', markersize=14)
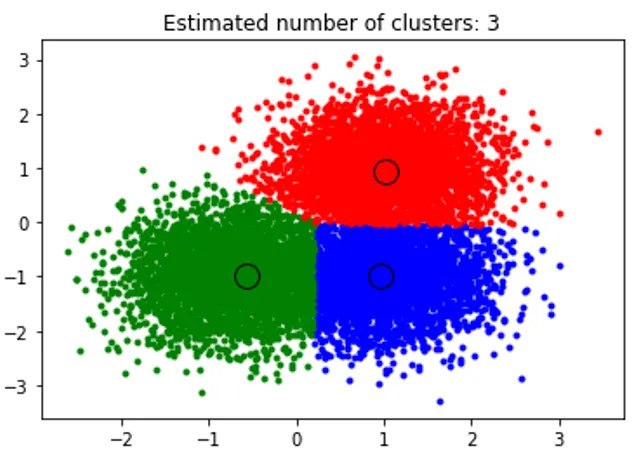
title('Estimated cluster numbers: %d'% n_clusters_)
show()
Vyššie uvedený úryvok vykonáva zhlukovanie a algoritmus našiel zhluky sústredené na každom bloku, ktorý sme vytvorili. Vidíme, že z nižšie uvedeného obrázka vyneseného útržkom ukazuje algoritmus stredného posunu schopný identifikovať počet klastrov potrebných v čase chodu a zistiť príslušnú šírku pásma, ktorá predstavuje dĺžku interakcie.
Výkon:
Príklad č. 2
Na základe segmentácie obrazu v počítačovom videní. Druhý úryvok preskúma, ako algoritmus priemerného posunu použitý v nástroji Deep Learning na segmentáciu farebného obrázka. Na identifikáciu priestorových zoskupení využívame algoritmus stredného posunu. V predchádzajúcom úryvku sme použili dvojrozmerný súbor údajov, zatiaľ čo v tomto príklade preskúmame priestor 3D. Pixel obrázka bude považovaný za údajový bod (r, g, b). Potrebujeme previesť obrázok do formátu poľa tak, aby každý pixel predstavoval dátový bod v obrázku, ktorý ideme do segmentu. Zhlukovanie hodnôt farieb v priestore vráti sériu zhlukov, kde pixely v klastri budú podobné RGB priestoru. Balíky použité na implementáciu stredného algoritmu posunu:
kód:
importnumpy as np
fromcluster importMeanShift, estimate_bandwidth
fromdatasets.samples_generator importmake_blobs
importpyplot as plt
fromitertools import cycle
fromPIL import Image
Pod útržkom môžete vykonať segmentáciu pôvodného obrázka:
#Segmentation of Color Image
img = Image.open('Sample.jpg.webp')
img = np.array(img)
#Need to convert image into feature array based
flatten_img=np.reshape(img, (-1, 3))
#bandwidth estimation
est_bandwidth = estimate_bandwidth(flatten_img,
quantile=.2, n_samples=500)
mean_shift = MeanShift(est_bandwidth, bin_seeding=True)
fit(flatten_img)
labels= mean_shift.labels_
# Plot image vs segmented image
figure(2)
subplot(1, 1, 1)
imshow(img)
axis('off')
subplot(1, 1, 2)
imshow(np.reshape(labels, (854, 1224)))
axis('off')
Generovaný obrázok uvádza, že tento prístup na identifikáciu tvarov obrazov a určenie priestorových zhlukov sa dá efektívne vykonať bez akéhokoľvek spracovania obrazu.
Výkon:


Výhody a aplikácie Priemerný algoritmus posunu
Nižšie sú uvedené výhody a použitie priemerného algoritmu:
- Často sa používa na riešenie počítačového videnia, kde sa používa na segmentáciu obrazu.
- Zhlukovanie údajových bodov v reálnom čase bez uvedenia počtu zhlukov.
- Veľmi dobre funguje v segmentácii obrázkov a sledovaní videa.
- Viac robustné pre odľahlé hodnoty.
Výhody stredného algoritmu posunu
Nižšie sú uvedené algoritmy priemerného posunu profilov:
- Výstup algoritmu je nezávislý od inicializácie.
- Procedúra je účinná, pretože má iba jeden parameter - šírku pásma.
- Žiadne predpoklady týkajúce sa počtu klastrov údajov a tvaru.
- Má lepší výkon ako K-Means Clustering.
Nevýhody stredného algoritmu posunu
Nižšie sú uvedené nevýhody algoritmu stredného posunu:
- Drahé pre veľké funkcie.
- V porovnaní s K-Means je klastrovanie veľmi pomalé.
- Výstup algoritmu závisí od šírky pásma parametra.
- Výstup závisí od veľkosti okna.
záver
Aj keď je to priamy prístup, ktorý sa primárne používal na riešenie problémov týkajúcich sa segmentácie obrazu, zoskupovania. Je porovnateľne pomalší ako prostriedok K-Means a je výpočtovo drahý.
Odporúčané články
Toto je sprievodca stredným algoritmom posunu. Tu diskutujeme o problémoch týkajúcich sa segmentácie obrazu, zhlukovania, výhod a dvoch funkcií jadra. Viac informácií nájdete aj v ďalších súvisiacich článkoch.
- K- znamená algoritmus zoskupovania
- KNN Algoritmus v R.
- Čo je to genetický algoritmus?
- Metódy jadra
- Metódy jadra v strojovom učení
- Detail Vysvetlenie algoritmu C ++