
Rozdiel medzi strojovým učením a prediktívnou analýzou
Strojové učenie je oblasť počítačovej vedy, ktorá v súčasnosti rastie skokom. Nedávny pokrok v hardvérových technológiách, ktorý vyústil do veľkého nárastu výpočtovej sily, ako napríklad GPU (jednotky grafického spracovania) a pokrok v neurónových sieťach, sa strojové učenie stalo bzučiacim slovom. V podstate pomocou techník strojového učenia môžeme zostaviť algoritmy na extrahovanie údajov a na zobrazenie dôležitých skrytých informácií. Prediktívna analytika je tiež časťou oblasti strojového učenia, ktorá je obmedzená na predpovedanie budúceho výsledku z údajov založených na predchádzajúcich modeloch. Aj keď sa prediktívna analytika používa už viac ako dve desaťročia najmä v bankovom a finančnom sektore, v poslednom čase sa aplikácia strojového učenia stala významnou pre algoritmy, ako je detekcia objektov z obrazov, klasifikácia textu a systémy odporúčaní.
Strojové učenie
Strojové učenie interne využíva štatistiku, matematiku a základy informatiky na vytváranie logiky pre algoritmy, ktoré dokážu robiť klasifikáciu, predikciu a optimalizáciu v reálnom čase, ako aj v dávkovom režime. Klasifikácia a regresia sú dve hlavné triedy problému strojového učenia. Poďme podrobne pochopiť strojové učenie a prediktívnu analýzu.
klasifikácia
V rámci týchto skupín problémov máme sklon klasifikovať objekt na základe jeho rôznych vlastností do jednej alebo viacerých tried. Napríklad klasifikácia klienta banky, aby bol oprávnený na pôžičku na bývanie alebo nie na základe svojej úverovej histórie. Zvyčajne by sme mali k dispozícii údaje o transakciách pre zákazníka, ako je jeho vek, príjem, vzdelanie, jeho pracovné skúsenosti, odvetvie, v ktorom pracuje, počet závislých osôb, mesačné výdavky, prípadné predchádzajúce pôžičky, jeho model výdavkov, úverová história atď. … a na základe týchto informácií by sme mali tendenciu počítať, či by mal dostať pôžičku alebo nie.
Existuje veľa štandardných algoritmov strojového učenia, ktoré sa používajú na vyriešenie problému klasifikácie. Logistická regresia je jednou z týchto metód, pravdepodobne najrozšírenejšou a najznámejšou, tiež najstaršou. Okrem toho máme aj niektoré z najpokročilejších a najkomplikovanejších modelov od rozhodovacieho stromu po náhodný les, podporu AdaBoost, podporu XP, podporu vektorových strojov, naivnú baizu a neurónovú sieť. Od posledných niekoľkých rokov prebieha hlboké vzdelávanie v popredí. Na klasifikáciu obrázkov sa zvyčajne používajú neurónové siete a hĺbkové vzdelávanie. Ak existuje sto tisíc obrázkov mačiek a psov a chcete napísať kód, ktorý dokáže automaticky oddeľovať obrázky mačiek a psov, možno budete chcieť ísť za metódami hlbokého učenia, ako je konvolučná neurónová sieť. Pochodeň, kaviareň, tok snímačov atď. Sú niektoré z populárnych knižníc v Pythone, ktoré sa učia hlboko.
Na meranie presnosti regresných modelov sa používajú metriky ako falošná pozitívna rýchlosť, falošne negatívna rýchlosť, citlivosť atď.
regresia
Regresia je ďalšou triedou problémov v strojovom učení, kde sa na rozdiel od klasifikačných problémov snažíme predpovedať spojitú hodnotu premennej namiesto triedy. Regresné techniky sa všeobecne používajú na predpovedanie ceny akcií na sklade, predajnej ceny domu alebo automobilu, dopytu po určitej položke atď. Keď sa do hry dostanú aj vlastnosti časových radov, problémy s regresiou sa stanú veľmi zaujímavými na vyriešenie. Lineárna regresia s obyčajným najmenším štvorcom je jedným z klasických algoritmov strojového učenia v tejto oblasti. Pre vzor založený na časových radoch sa používajú ARIMA, exponenciálny kĺzavý priemer, vážený kĺzavý priemer a jednoduchý kĺzavý priemer.
Na meranie presnosti regresných modelov sa používajú metriky, ako je stredná chyba chyby, absolútna stredná chyba chyby, druhá odmocnina chyby atď.
Prediktívne analýzy
Existuje niekoľko oblastí prekrývania medzi strojovým učením a prediktívnou analýzou. Zatiaľ čo bežné techniky, ako je logistická a lineárna regresia, patria do strojového učenia a prediktívnej analýzy, pokročilé algoritmy ako strom rozhodovania, náhodný les atď. Sú v podstate strojovým učením. Podľa prediktívnej analýzy zostáva cieľ problémov veľmi úzky, ak je zámerom vypočítať hodnotu konkrétnej premennej v budúcnosti. Prediktívna analytika je zaťažená štatistikou, zatiaľ čo strojové učenie je skôr zmesou štatistík, programovania a matematiky. Typický prediktívny analytik trávi svoj čas výpočtom t-námestia, štatistiky, Innova, chi-square alebo obyčajného najmenšieho štvorca. Otázky, ako je to, či sú údaje bežne distribuované alebo skreslené, ak sa použije distribúcia študenta alebo sa použije zvonicová krivka, by sa mali brať alfa vždy po 5% alebo 10%. Detailne hľadajú diabla. Strojový učiteľ sa neobťažuje s mnohými z týchto problémov. Ich bolesti hlavy sú úplne odlišné a zistili, že sú prilepené na zlepšení presnosti, falošne pozitívnej minimalizácii rýchlosti, manipulácii s odľahlými hodnotami, normalizácii rozsahu alebo k násobnom overení.
Prediktívny analytik väčšinou používa nástroje, ako je Excel. Scenár alebo cieľ sú ich obľúbené. Príležitostne používajú VBA alebo mikroskop a ťažko zapisujú akýkoľvek zdĺhavý kód. Strojový učiteľ trávi celý svoj čas písaním komplikovaného kódu nad rámec bežného porozumenia, používa nástroje ako R, Python, Saas. Programovanie je ich hlavnou prácou, opravou chýb a testovaním rôznych krajín je každodennou rutinou.
Tieto rozdiely tiež prinášajú zásadný rozdiel v ich dopyte a mzde. Aj keď sú prediktívni analytici takí včera, strojové učenie je budúcnosť. Typický strojový učiteľ alebo vedec údajov (ako sa v týchto dňoch väčšinou nazýva) dostáva 60-80% viac ako typický softvérový inžinier alebo prediktívny analytik v tejto veci a sú kľúčovým faktorom v dnešnom svete technológií. Uber, Amazon a teraz aj vozidlá s vlastným pohonom sú možné len kvôli nim.
Porovnanie hlava-hlava medzi strojovým učením a prediktívnou analýzou (infografika)
Nižšie je prvých 7 porovnávaní medzi strojovým učením a prediktívnou analýzou
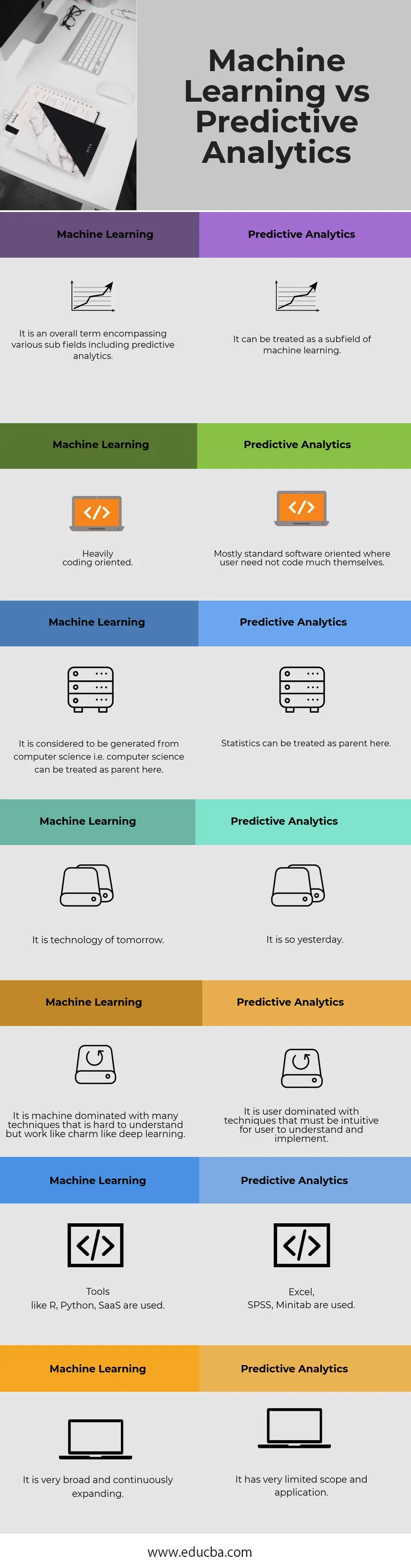
Tabuľka strojového učenia verzus prediktívna analýza Analytics
Nižšie je uvedené podrobné vysvetlenie Machine Learning vs Predictive Analytics
| Strojové učenie | Prediktívne analýzy |
| Je to celkový pojem zahŕňajúci rôzne podpolia vrátane prediktívnej analýzy. | Môže sa to považovať za podpolí strojového učenia. |
| Silne orientované na kódovanie. | Väčšinou sa jedná o softvérovo orientovaný program, pri ktorom používateľ nemusí príliš kódovať |
| Má sa za to, že pochádza z počítačovej vedy, tj počítačová veda sa tu môže považovať za rodiča. | So štatistikou sa tu dá zaobchádzať ako s rodičom. |
| Je to technológia zajtrajška. | Je to včera. |
| Je to stroj, ktorému dominujú mnohé techniky, ktorým je ťažké porozumieť, ale fungujú ako kúzlo ako hlboké učenie. | Používateľovi dominujú techniky, ktoré musia byť pre používateľa intuitívne, aby ich pochopili a implementovali. |
| Používajú sa nástroje ako R, Python, SaaS. | Používajú sa Excel, SPSS, Minitab. |
| Je veľmi široký a neustále sa rozširuje. | Má veľmi obmedzený rozsah a použitie. |
Záver - Strojové učenie vs prediktívne analýzy
Z vyššie uvedenej diskusie o strojovom učení a prediktívnej analýze je zrejmé, že prediktívna analytika je v podstate čiastkovým poľom strojového učenia. Strojové učenie je všestrannejšie a dokáže vyriešiť celý rad problémov.
Odporúčaný článok
Toto bol návod na strojové učenie verzus prediktívne analýzy, ich význam, porovnanie medzi dvoma hlavami, kľúčové rozdiely, porovnávacie tabuľky a závery. Ďalšie informácie nájdete aj v nasledujúcich článkoch -
- Naučte sa strojové učenie Big Data Vs
- Rozdiel medzi Data Science vs Machine Learning
- Porovnanie prediktívnej analýzy s údajovou vedou
- Prediktívna analýza Analytics Analytics Vs - Ktorá z nich je užitočná