

Úvod do architektúry Hadoop
Hadoop Architecture je framework s otvoreným zdrojovým kódom, ktorý pomáha pri ľahkom spracovaní veľkých súborov údajov. Pomáha pri vytváraní aplikácií, ktoré spracúvajú obrovské dáta rýchlejšie. Využíva distribuované výpočtové koncepty, pri ktorých sa údaje šíria cez rôzne uzly klastra. Aplikácie, ktoré sú vytvorené pomocou Hadoop, využívajú komoditné počítače. Tieto počítače sú na trhu ľahko dostupné za nízke ceny. Tento výsledok dosahuje vyššiu výpočtovú silu pri nízkych nákladoch. Všetky údaje nachádzajúce sa v Hadoop sa nachádzajú v systéme HDFS namiesto v miestnom systéme súborov. HDFS je distribuovaný súborový systém Hadoop. Tento model je založený na dátovej lokalite, kde sa výpočtová logika posiela do uzlov nachádzajúcich sa v klastri, ktorý obsahuje údaje. Táto logika nie je nič iné ako logika, ktorá zostavuje program.
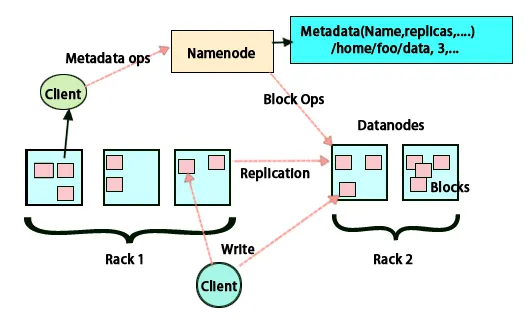
Hadoop Architecture
Základnou myšlienkou tejto architektúry je, že celé ukladanie a spracovanie sa uskutočňuje v dvoch krokoch a dvoma spôsobmi. Prvým krokom je spracovanie, ktoré sa vykonáva programom Map redu a druhým krokom je ukladanie údajov, ktoré sa robia na HDFS. Má architektúru master-slave na ukladanie a spracovanie údajov. Hlavným uzlom pre ukladanie údajov v Hadoop je uzol s menom. K dispozícii je tiež hlavný uzol, ktorý vykonáva monitorovanie a porovnáva spracovanie údajov pomocou Hadoop Map Reduce. Otroky sú ďalšie stroje v klastri Hadoop, ktoré pomáhajú pri ukladaní údajov a tiež vykonávajú zložité výpočty. Každý podradený uzol bol priradený sledovači úloh a dátový uzol má sledovač úloh, ktorý pomáha pri vykonávaní procesov a ich účinnej synchronizácii. Tento typ systému je možné nastaviť buď v cloude, alebo v premise. Uzol Name je jediný bod zlyhania, keď nie je spustený v režime vysokej dostupnosti. Architektúra Hadoop tiež obsahuje ustanovenie na udržiavanie uzla stand-by name s cieľom chrániť systém pred zlyhaniami. Predtým existovali uzly sekundárneho názvu, ktoré fungovali ako záloha, keď bol uzol primárneho názvu vypnutý.
FSimage and Edit Log
Protokol FSimage a Edit zabezpečuje perzistenciu metadát súborového systému, aby držali krok so všetkými informáciami a názov uzla ukladá metadáta do dvoch súborov. Tieto súbory sú FSimage a protokol úprav. Úlohou spoločnosti FSimage je uchovávať úplnú snímku systému súborov v danom čase. O zmenách, ktoré sa neustále vykonávajú v systéme, je potrebné viesť záznamy. Tieto prírastkové zmeny, ako napríklad premenovanie alebo pripojenie podrobností k súboru, sa ukladajú do protokolu úprav. Rámec poskytuje lepšiu voľbu ako vytvorenie nového FSimage zakaždým, lepšou možnosťou je ukladanie údajov pri vytvorení nového súboru pre FSimage. FSimage vytvorí novú snímku pri každej zmene. Ak uzol Name zlyhá, môže obnoviť predchádzajúci stav. Uzol sekundárneho názvu môže tiež aktualizovať svoju kópiu vždy, keď dôjde k zmenám v protokoloch FSimage a editovať. Takto sa zabezpečí, že aj keď je uzol mena vypnutý, v prítomnosti sekundárneho uzla mena nedôjde k strate údajov. Uzol názvu nevyžaduje, aby sa tieto obrazy museli znovu načítať do sekundárneho uzla názvu.
Replikácia dát
HDFS je určený na rýchle spracovanie údajov a poskytovanie spoľahlivých údajov. Ukladá údaje medzi počítačmi a vo veľkých klastroch. Všetky súbory sú uložené v sérii blokov. Tieto bloky sa replikujú kvôli odolnosti voči chybám. O veľkosti bloku a replikačnom faktore môžu rozhodnúť užívatelia a nakonfigurovať ich podľa požiadaviek používateľa. V predvolenom nastavení je replikačný faktor 3. Replikačný faktor možno určiť v čase vytvorenia súboru a neskôr ho môžete zmeniť. Všetky rozhodnutia týkajúce sa týchto replík sa prijímajú podľa názvu uzla. Uzol mena udržuje pravidelné posielanie prezenčných signálov a blokovanie správ pre všetky dátové uzly v klastri. Prijatie prezenčného signálu znamená, že dátový uzol funguje správne. Správa o bloku určuje zoznam všetkých blokov prítomných v dátovom uzle.
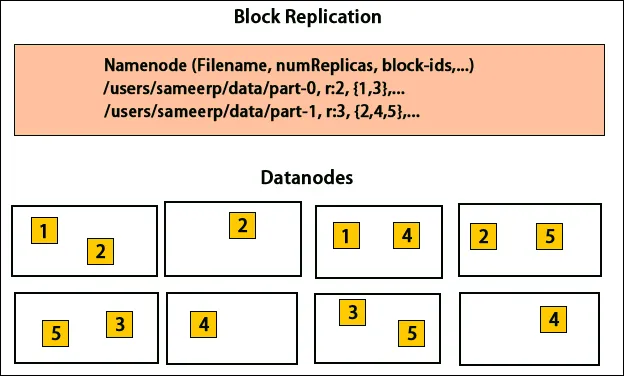
Ukladanie replík
Umiestňovanie replík je v spoločnosti Hadoop veľmi dôležitou úlohou pre spoľahlivosť a výkon. Všetky rôzne dátové bloky sú umiestnené na rôznych stojanoch. Implementácia umiestnenia replík môže byť uskutočnená podľa spoľahlivosti, dostupnosti a využitia šírky pásma siete. Klaster počítačov sa môže šíriť do rôznych stojanov. Na jeden stojan nie je možné umiestniť viac ako dva uzly. Tretia replika by sa mala umiestniť na iný stojan, aby sa zabezpečila väčšia spoľahlivosť údajov. Dva uzly na stojane komunikujú prostredníctvom rôznych prepínačov. Názvový uzol má ID racku pre každý dátový uzol. Avšak umiestnenie všetkých uzlov na rôzne stojany zabraňuje strate akýchkoľvek údajov a umožňuje využitie šírky pásma z viacerých stojanov. Znižuje tiež medziproduktový prenos a zlepšuje výkon. Pravdepodobnosť zlyhania stojana je tiež veľmi menšia v porovnaní so zlyhaním uzla. Znižuje celkovú šírku pásma siete pri čítaní údajov z dvoch jedinečných stojanov, a nie z troch.
Mapa Znížiť
Mapa Reduce sa používa na spracovanie údajov uložených na HDFS. Píše distribuované údaje v distribuovaných aplikáciách, čo zaisťuje efektívne spracovanie veľkého množstva údajov. Spracúvajú na veľkých klastroch a vyžadujú komoditu, ktorá je spoľahlivá a odolná voči chybám. Jadrom programu Map-reduction môžu byť tri operácie ako mapovanie, zhromažďovanie párov a premiešanie výsledných údajov.
Záver - architektúra Hadoop
Hadoop je open source framework, ktorý pomáha v systéme odolnom voči poruchám. Môže ukladať veľké množstvo údajov a pomáha pri ukladaní spoľahlivých údajov. Obe časti ukladania údajov do systému HDFS a ich spracovanie pomocou mapy znižujú pomoc pri správnom a účinnom fungovaní. Má architektúru, ktorá pomáha pri správe všetkých blokov údajov a tiež má najnovšiu kópiu uložením do protokolu FSimage a úprav protokolov. Faktor replikácie tiež pomáha pri získavaní kópií údajov a ich získavaní späť vždy, keď dôjde k zlyhaniu. HDFS tiež presunie odstránené súbory do koša adresára pre optimálne využitie miesta.
Odporúčané články
Toto bol sprievodca architektúry Hadoop. Diskutovali sme tu o architektúre, znížení mapy, umiestnení replík, replikácii údajov. Viac informácií nájdete aj v ďalších navrhovaných článkoch -
- Staňte sa vývojárom spoločnosti Hadoop
- Úvod do systému Android
- Čo je Tableau? | Prehľad
- Čo je MapReduce v Hadoope?