

Čo je to Big Data a Hadoop?
Dáta rastú exponenciálne každý deň as týmito rastúcimi údajmi prichádza potreba ich využívať. Rovnako ako v predchádzajúcich dňoch sme mali diskety na ukladanie údajov a prenos údajov bol tiež pomalý, ale v súčasnosti sú tieto nedostatky nedostatočné a cloudové úložisko sa používa, pretože máme terabajty údajov. V dnešnom svete máme sociálne médiá, ktoré sa najviac podieľajú na raste údajov. Pozostáva z správania ľudí, spôsobu myslenia a niekoľkých ďalších aspektov. Hovorí sa, že za každú minútu sa na YouTube nahrá 300 hodín videa, na Facebook a mnoho ďalších sa nahrá viac ako 20 miliónov fotografií. Okrem toho neexistuje správna štruktúra prenášaných údajov, čo je najväčšou výzvou na ich spracovanie.
Keďže sa pri vysokej rýchlosti vytvárajú obrovské údaje, tradičné systémy RDBMS nedokázali zvládnuť taký rýchly rast. Navyše nedokážu spracovať ani neštruktúrované údaje. Je veľmi ťažké zvládnuť také obrovské množstvo heterogénnych údajov, ktoré rýchlo rastú, a spracovávať tieto dáta vysokou rýchlosťou spracovania. Preto vznikla potreba takého systému, ktorý je schopný efektívne spracovať veľké súbory údajov. Z tohto dôvodu vznikol Hadoop. HDFS je komponent spoločnosti Hadoop, ktorý riešil problém veľkého súboru údajov pomocou úložného priestoru pomocou distribuovaného úložného priestoru, zatiaľ čo YARN je zložka, ktorá riešila problém spracovania a drasticky skrátila dobu spracovania.
Hadoop je softvér s otvoreným zdrojovým kódom na ukladanie a spracovanie veľkých súborov údajov pomocou distribuovaného veľkého zhluku komoditného hardvéru. Vyvinuli ho Doug Cutting a Michael J. Cafarella a licencovali ich pod Apache. Je napísaný pomocou Java a bol vyvinutý na základe článku napísaného spoločnosťou Google v systéme MapReduce a aplikuje koncepty funkčného programovania. Je spoľahlivý, ekonomický flexibilný a škálovateľný.
Základné komponenty Hadoopu
Základné komponenty Hadoopu sú nasledujúce
-
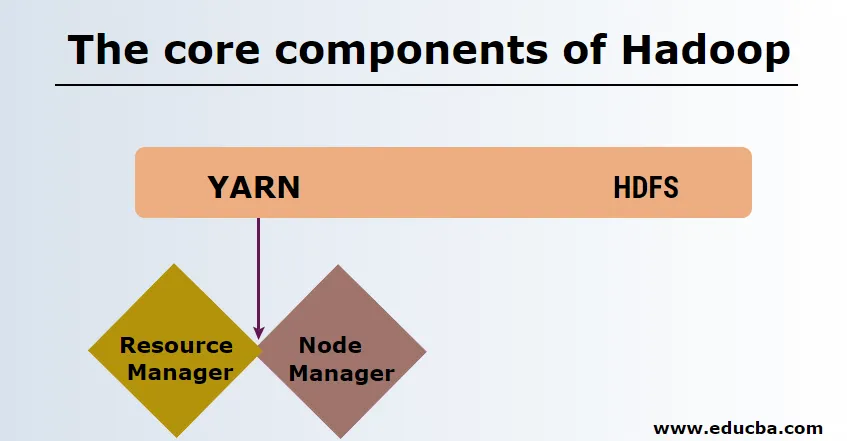
HDFS
Distribuovaný súborový systém HDFS alebo Hadoop má Namenode a dátový uzol. Namenode je hlavný uzol, na ktorom je spustený hlavný démon, ktorý riadi dátové uzly a sleduje všetky operácie. Datanódy sú otroky, v ktorých sú dáta skutočne uložené.
-
nite
YARN pozostáva z dvoch hlavných komponentov:
1. ResourceManager: Beží na hlavnom uzle a riadi všetky zdroje a naplánuje všetky aplikácie. Má Plánovač a ApplicationManager.
2. NodeManager: Beží na každom slave uzle a je zodpovedný za správu kontajnerov a monitorovanie využívania zdrojov.
Niekoľko komponentov Hadoop
Existuje niekoľko komponentov Hadoopu, ako sú ošípané, úľ, strecha, flume, mahout, oozie, zookeeper, HBase atď.
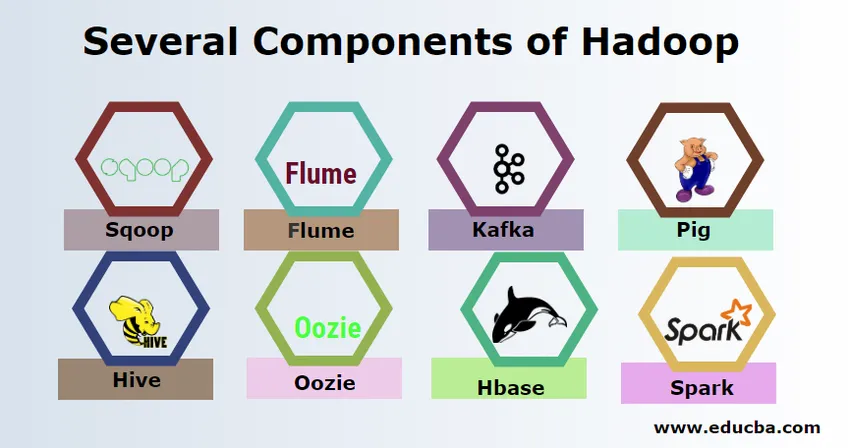
- Sqoop - Používa sa na import a export údajov z RDBMS do Hadoop a naopak.
- Flume - Používa sa na načítanie údajov v reálnom čase do systému Hadoop.
- Kafka - Jedná sa o systém zasielania správ používaný na smerovanie údajov v reálnom čase do systému Hadoop.
- Pig - Používa sa ako skriptovací jazyk na spracovanie údajov.
- Podregister - Je to rámec skladovania údajov postavený na HDFS, takže užívatelia, ktorí sú oboznámení s SQL, môžu vykonávať dotazy na získanie údajov. Tieto dotazy sa nazývajú HiveQL.
- Oozie - Používa sa na naplánovanie pracovného toku úloh, ktoré sa majú spúšťať pri určených udalostiach alebo čase.
- Hbase - Jedná sa o databázu SQL, ktorá nie je súčasťou Apache Hadoop.
- Spark - Používa sa na spracovanie v pamäti, ktoré je omnoho rýchlejšie ako redukcia mapy Hadoop.
Poskytovatelia Hadoop
Existuje veľa spoločností ponúkajúcich distribúciu Hadoop. Nižšie je uvedených niekoľko najlepších poskytovateľov pre spoločnosť Hadoop:
- Cloudera
- Hortonworks
- Mapro
Existuje niekoľko predpokladov pre učenie sa Hadoop. Potrebné sú predchádzajúce skúsenosti s jazykom Java a skriptovacím jazykom. Aj keď Hadoop už má vlastné programovacie jazyky na vysokej úrovni, ako napríklad ošípané a úľ, ktoré generujú backendový kód pre ďalšie spracovanie, stále je možné vytvoriť vlastný program na zníženie mapy, ktorýkoľvek programovací jazyk ako Ruby, Python, Perl a dokonca aj programovanie v jazyku C.
Bigdata a Hadoop sú na dnešnom trhu veľmi žiadané. V nadchádzajúcich dňoch sa to ešte zvýši. Mnoho organizácií sa už presťahovalo do spoločnosti Hadoop a tí, ktorí sa čoskoro nebudú presťahovať. V súčasnosti existuje správa, ktorá uvádza, že veľké spoločnosti začali investovať do analýzy veľkých údajov. Prognóza veľkého dátového marketingu má vždy vzostupný trend a vôbec to nie je krátkodobý stav. Okrem všetkých týchto pracovných miest v spoločnosti Hadoop a veľkých dát sa vždy ponúkajú vysoké mzdy v porovnaní s inými technológiami.
Najlepšie spoločnosti s veľkými dátami a firmami Hadoop
Nižšie je uvedených niekoľko najlepších spoločností, ktoré zamestnávajú najväčší počet zdrojov spoločnosti Hadoop.
- yahoo
- Amazonka
- Royal Bank of Scotland
- British Airways
- Expedia
- Walmart
Existuje veľa spoločností, ktoré používajú veľké dátové aplikácie. Sú to tieto:
-
nokia
Pre aplikáciu používa komponenty Cloudera a Hadoop ako HDFS, HBase, Sqoop, Scribe. Používal používateľské dáta efektívne na pochopenie a zlepšenie používateľského komfortu. Využíva spracovanie údajov a komplexné analýzy na tvorbu mapy s prediktívnym prenosom a vrstvenými výškovými modelmi.
-
SAS
Spolupracovala s firmou Hadoop s cieľom pomôcť vedcom údajov získať lepší prehľad poskytnutím prostredia, ktoré poskytuje vizuálne a interaktívne skúsenosti a pomáha tak objavovať nové trendy. Analytické programy extrahujú zmysluplné informácie z údajov a technológia v pamäti pomáha k rýchlejšiemu prístupu k údajom.
Existuje tiež mnoho ďalších spoločností, ktoré používajú veľké dátové platformy na rôzne analýzy. Ide o analýzu údajov o letoch čiernej skrinky v leteckom priemysle, rozdielnu analýzu na akciovom trhu atď.
Výhody Haddopu
Nižšie je uvedených niekoľko výhod systému Hadoop
- Škálovateľná - Na rozdiel od tradičných RDBMS je to vysoko škálovateľná platforma, pretože dokáže ukladať veľké množiny údajov v distribuovaných klastroch nad komoditným hardvérom, ktorý pracuje paralelne.
- Nákladovo efektívne - náklady na RDBMS boli príliš vysoké na ukladanie údajov, ktoré sa v Hadoopu uľavili.
- Rýchly a flexibilný - Ponúka rýchly prístup k údajom prostredníctvom distribuovaného systému súborov. Ponúka tiež odvodenie obchodných poznatkov z čiastočne štruktúrovaných a neštruktúrovaných údajov.
- Odolný voči poruchám - Kedykoľvek sa do uzla posielajú akékoľvek údaje, rovnaké údaje sa replikujú do iných uzlov, ku ktorým sa dá pristupovať v prípade akejkoľvek poruchy prvého uzla.
Záver - čo sú Big Data a Hadoop
Dáta neustále rastú, a preto bude vždy potrebné veľké dáta a spoločnosť Hadoop bude mať z týchto údajov zmysel. Z tohto dôvodu budú odborníci so znalosťami spoločnosti Hadoop v nadchádzajúcich dňoch vždy nájsť dostatok príležitostí a môžu byť zásadným prínosom pre organizáciu, ktorá podporuje podnikanie a ich kariéru.
Odporúčané články
Toto bola príručka o tom, čo je Big Data a Hadoop. Tu sme diskutovali základné pojmy a komponenty veľkých dát a Hadoop. Viac informácií nájdete aj v nasledujúcom článku -
- Príklady veľkých dátových analýz
- Použitie Hadoopu
- Sprievodca vizualizáciou údajov
- Čo je to veľká dátová analytika?