
Úvod do architektúry úľov
Architektúra úľa je postavená na vrchole ekosystému Hadoop. Úľ často komunikuje s Hadoopom. Apache Hive sa vyrovnáva s databázovým systémom SQL domény a mapovým znížením. Úľové aplikácie sa dajú písať v rôznych jazykoch ako Java, Python. Architektúra podregistra ukazuje, ako napísať jazyk dotazu úľa a ako sa interakcie medzi programátorom robia pomocou rozhrania príkazového riadka. Jazyk dotazu úľa robí úlohu prevodu všetkých úloh klastra Hadoop pomocou zmenšenia mapy. Ako sme všetci vedeli, spoločnosť Hadoop spracúva veľké údaje v distribuovanom prostredí a vytvára rámec s otvoreným zdrojovým kódom. S úľom je flexibilné spravovať a vykonávať dotaz a dobrým podporovateľom je vykonávanie funkcií, ako je zapuzdrenie alebo dotazy ad hoc. Tento článok poskytuje stručný úvod do architektúry úľa, ktorá sa nachádza na vrstve Hadoop, na vykonanie zhrnutia veľkých dát.
Architektúra úľa s jeho súčasťami
Úľ hrá hlavnú úlohu pri analýze údajov a integrácii podnikových informácií a podporuje formáty súborov, ako sú textový súbor, rc súbor. Hive používa distribuovaný systém na spracovanie a vykonávanie dotazov a ukladanie sa nakoniec robí na disku a nakoniec sa spracuje pomocou rámca na zníženie mapy. Rieši problém s optimalizáciou nájdený v rámci mapy-redukcie a podregister vykonáva dávkové úlohy, ktoré sú jasne vysvetlené v pracovnom postupe. Tu ukladá meta obchod informácie o schéme. Rámec s názvom Apache Tez je navrhnutý pre výkon dotazov v reálnom čase.
Hlavné komponenty úľa sú uvedené nižšie:
- Úľ klientov
- Úľové služby
- Úľový úložný priestor (úložisko Meta)
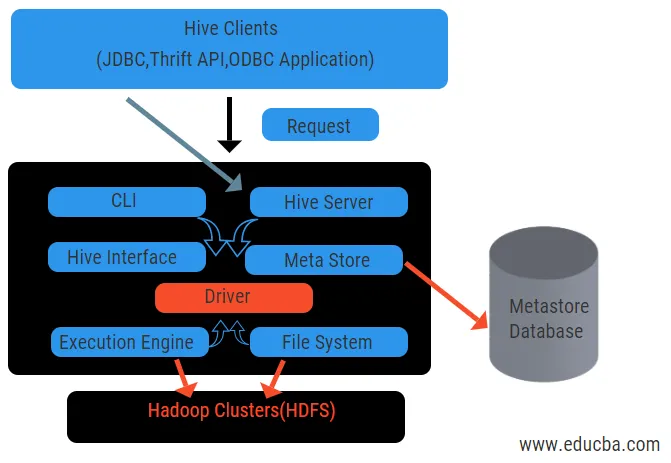
Vyššie uvedený diagram ukazuje architektúru Úľa a jeho komponentov.
Klienti úľa:
Zahŕňajú aplikáciu Thrift na vykonávanie jednoduchých príkazov úľa, ktoré sú k dispozícii pre python, ruby, C ++ a ovládače. Výhody týchto klientskych aplikácií na vykonávanie otázok v úli. Úľ má tri typy kategorizácie klientov: šetrní klienti, klienti JDBC a ODBC.
Služby úľa:
Na spracovanie všetkých podregistrov otázok existujú rôzne služby. Všetky funkcie sú ľahko definované užívateľom v úli. Pozrime sa stručne na všetky tieto služby:
- Rozhranie príkazového riadku (User Interface): Umožňuje interakciu medzi používateľom a úľom, predvoleným shellom. Poskytuje GUI na vykonávanie príkazového riadka a prehľadu úľa. Na odosielanie otázok a interakcií s webovým prehliadačom môžeme použiť aj webové rozhranie (HWI).
- Ovládač úľa: Prijíma dotazy z rôznych zdrojov a klientov, ako je napríklad server Thrift, a ukladá a vyvoláva ovládače ODBC a JDBC, ktoré sú automaticky pripojené k úlu. Táto súčasť vykonáva sémantickú analýzu toho, ako vidí tabuľky z metastora, ktorý analyzuje dotaz. Ovládač využíva kompilátor a vykonáva funkcie, ako je syntaktický analyzátor, plánovač, vykonávanie úloh MapReduce a optimalizátor.
- Kompilátor: Analýzu a sémantický proces dotazu vykonáva kompilátor. Konvertuje dotaz na abstraktný syntaxový strom a znova na kompatibilitu s DAG. Optimalizátor potom rozdelí dostupné úlohy. Úlohou vykonávateľa je vykonávať úlohy a monitorovať časový rozvrh úloh.
- Execution Engine: Všetky dotazy sú spracovávané exekučným motorom. Programy etáp DAG sú vykonávané motorom a pomáhajú pri riadení závislostí medzi dostupnými etapami a pri ich vykonávaní na správnom komponente.
- Metastore: Funguje ako centrálny archív na ukladanie všetkých štruktúrovaných informácií o metadátach. Je to tiež dôležitá súčasť úľa, pretože obsahuje informácie, ako sú tabuľky a podrobnosti o rozdelení a ukladanie súborov HDFS. Inými slovami, povieme, že metastore funguje ako priestor mien pre tabuľky. Metastore sa považuje za samostatnú databázu, ktorú zdieľajú aj iné komponenty. Metastore má dva kusy nazývané service a backlog storage.
Dátový model úľa je štruktúrovaný do oddielov, vedier, tabuliek. Všetky tieto položky je možné filtrovať, mať kľúče oddielov a vyhodnotiť dopyt. Dotaz úľa funguje na rámci Hadoop, nie na tradičnej databáze. Server podregistra je rozhranie medzi dopytmi vzdialeného klienta do podregistra. Spúšťací mechanizmus je úplne zabudovaný v serveri úľa. Aplikáciu úľa môžete nájsť v strojovom vzdelávaní, v obchodnom spravodajstve v detekčnom procese.
Pracovný tok úľa:
Úľ funguje v dvoch typoch režimov: interaktívny režim a neinteraktívny režim. Bývalý režim umožňuje všetkým príkazom úľa ísť priamo do shellu úľa, zatiaľ čo neskorší typ vykoná kód v konzolovom režime. Údaje sú rozdelené do oddielov, ktoré sa ďalej delia na vedrá. Realizačné plány sú založené na agregácii a skreslení údajov. Ďalšou výhodou použitia úľa je to, že ľahko spracúva veľké množstvo informácií a má viac používateľských rozhraní.
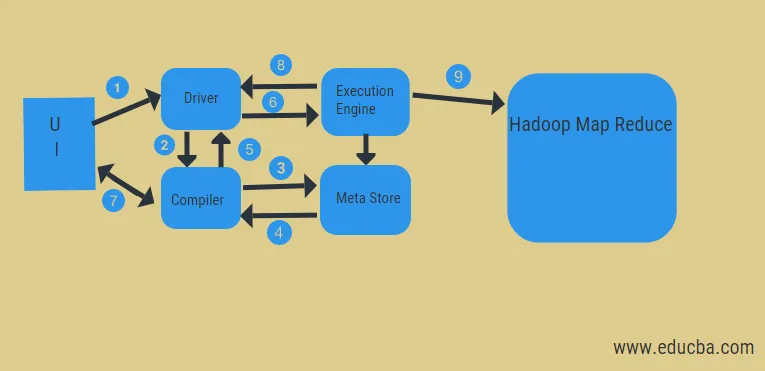
Z horeuvedeného diagramu môžeme pomocou systému Hadoop nahliadnuť do toku údajov v úli.
Tieto kroky zahŕňajú:
- vykonajte dopyt z používateľského rozhrania
- získať plán z DAG fázy vodiča úlohy
- získať žiadosť o metaúdaje z obchodu s metaúdajmi
- poslať metadáta z kompilátora
- zaslanie plánu späť vodičovi
- Vykonajte plán vo vykonávacom nástroji
- načítanie výsledkov pre príslušný dopyt používateľa
- odosielanie výsledkov obojsmerne
- spracovanie procesného modulu v HDFS s výsledkami mapovania a načítania z dátových uzlov vytvorených sledovačom úloh. funguje ako spojka medzi Hive a Hadoop.
Úlohou vykonávacieho modulu je komunikovať s uzlami, aby sa získali informácie uložené v tabuľke. Tu sa vykonávajú operácie SQL, ako je vytvorenie, presunutie alebo zmena, aby sa získal prístup k tabuľke.
záver:
Prešli sme architektúrou úľov a ich pracovným tokom, úľ v podstate vykonáva množstvo údajov v petabajtoch, a preto ide o balík dátového skladu na platforme Hadoop. Keďže úľ je dobrou voľbou pri spracovaní veľkého objemu údajov, pomáha pri príprave údajov pomocou sprievodcu rozhraním SQL, aby vyriešil problémy MapReduce. Úľ Apache je nástroj ETL na spracovanie štruktúrovaných údajov. Poznanie architektúry úľa pomáha podnikovým ľuďom pochopiť princíp fungovania úľa a má dobrý začiatok s programovaním úľa.
Odporúčané články:
Toto bol sprievodca architektúry Úľov. Tu diskutujeme o architektúre úľa, rôznych komponentoch a pracovnom postupe úľa. môžete sa tiež pozrieť na nasledujúce články a dozvedieť sa viac-
- Hadoop Architecture
- Použitie Ruby
- Čo je C ++
- Čo je MySQL databáza
- Usporiadať úľ podľa