

Úvod do Apache Flume
Apache Flume je Framework na príjem dát, ktorý zapisuje údaje založené na udalostiach do distribuovaného systému súborov Hadoop. Je známe, že spoločnosť Hadoop spracúva veľké údaje, vzniká otázka, ako sa údaje generované z rôznych webových serverov prenášajú do systému súborov Hadoop? Odpoveď je Apache Flume. Flume je navrhnutý na prijímanie údajov o veľkom objeme údajov Hadoop na základe udalostí.
Zvážte scenár, v ktorom počet webových serverov generuje protokolové súbory a tieto protokolové súbory je potrebné preniesť do súborového systému Hadoop. Flume zhromažďuje tieto súbory ako udalosti a vysiela ich do spoločnosti Hadoop. Aj keď sa Flume používa na prenos do Hadoopu, neexistuje pevné pravidlo, že cieľom musí byť Hadoop. Flume je schopný písať do iných rámcov ako Hbase alebo Solr.
Flume Architecture
Všeobecne sa architektúra Apache Flume skladá z nasledujúcich komponentov:
- Flume Source
- Flume Channel
- Flume Sink
- Flume Agent
- Flume Event
Pozrime sa stručne na každú zložku Flume
1. Flume Source
Zdroj Flume je prítomný v generátoroch údajov, ako sú Face book alebo Twitter. Zdroj zhromažďuje údaje od generátora a prenáša ich do kanála Flume Channel vo forme Flume Events. Flume podporuje rôzne typy zdrojov, ako napríklad Avro Flume Source - pripája sa na port Avro a prijíma udalosti od externého klienta Avro, Thrift Flume Source - pripája sa na port Thrift a prijíma udalosti z externých tokov Thrift klientov, zdroja spoolových adresárov a zdroja Kafka Flume.
2. Flume Channel
Intermediate Store, ktorý ukladá do vyrovnávacej pamäte udalosti odosielané zdrojom Flume Source, kým ich nespotrebuje Sink, sa nazýva Flume Channel. Kanál funguje ako prechodný most medzi zdrojom a drezom. Kanály žľabov majú transakčný charakter.
Aplikácia Flume poskytuje podporu pre kanál File a Memory channel. Kanál súborov je svojou povahou trvalý, to znamená, že po zápise údajov do kanála sa nestratia, hoci ak sa agent reštartuje. V pamäti sú udalosti kanálov uložené v pamäti, takže to nie je trvanlivé, ale vo svojej podstate veľmi rýchle.
3. Flume Sink
Flume Sink je prítomný v dátových úložiskách ako HDFS, HBase. Umývadlo na flume spotrebováva udalosti z kanála a ukladá ich do cieľových obchodov, ako je HDFS. Neexistuje pravidlo, že by umývadlo malo doručovať udalosti do obchodu, namiesto toho ho môžeme nakonfigurovať tak, aby umývadlo mohlo doručovať udalosti inému agentovi. Flume podporuje rôzne umývadlá ako sú HDFS Sink, Hive Sink, Thrift Sink, Avro Sink.
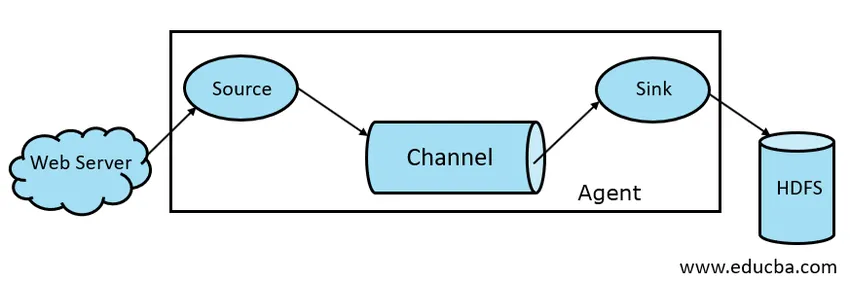
Obr. 1.1 Základná architektúra žľabu
4. Flume Agent
Agent Flume je dlhotrvajúci proces Java, ktorý beží na kombinácii zdroj - kanál - umývadlo. Flume môže mať viac ako jedného agenta. Flume môžeme považovať za súbor prepojených agentov Flume, ktoré sú distribuované v prírode.
5. Flume Event
Udalosť je jednotka údajov prenášaných v službe Flume . Všeobecná reprezentácia dátového objektu vo Flume sa nazýva Event. Udalosť sa skladá z užitočného zaťaženia bajtového poľa s voliteľnými hlavičkami.
Spracovanie Flume
Agent Flume je proces java, ktorý sa skladá z Source - Channel - Sink vo svojej najjednoduchšej forme. Zdroj zhromažďuje údaje od generátora údajov vo forme Udalosti a dodáva ich na Kanál. Zdroj môže dodávať do viacerých kanálov podľa požiadavky. Fan out je proces, pri ktorom sa jeden zdroj zapíše na viac kanálov, aby sa mohli doručiť na viac umývadiel.
Udalosť je základná jednotka dát prenášaných v službe Flume. Kanál ukladá údaje do vyrovnávacej pamäte, kým ich nespustí Sink. Sink zhromažďuje údaje z kanála a dodáva ich do Centralizovaného ukladania údajov, ako je HDFS alebo Sink, môže tieto udalosti podľa potreby poslať inému agentovi Flume.
Flume podporuje transakcie. Na dosiahnutie spoľahlivosti používa Flume samostatné transakcie od zdroja k kanálu a od kanála k potopeniu. Ak sa udalosti nedodajú, transakcia sa vráti späť a neskôr sa znova doručí.
Aby sme porozumeli fungovaniu Flume, vezmime si príklad konfigurácie Flume, kde zdrojom je spoolový adresár a drez je Hdfs. V tomto príklade je agent Flume v najjednoduchšej forme, tj topológia jedného zdroja - kanála - drez, ktorá je nakonfigurovaná pomocou súboru vlastností java.
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel1
agent1.sources.source1.type = spooldir
agent1.sources.source1.spoolDir = /tmp/spooldir
agent1.sinks.sink1.type = hdfs
agent1.sinks.sink1.hdfs.path = /tmp/flume
agent1.channels.channel1.type = file
Vo vyššie uvedenom príklade konfigurácie je agent základom, s ktorým definujeme ďalšie vlastnosti. source1 a sink1 a channel1 sú názvy zdroja, drezu a kanála a ich typy a umiestnenia sú tiež zodpovedajúcim spôsobom uvedené.
Výhody Apache Flume
- Flume je vo svojej podstate škálovateľný, spoľahlivý a odolný voči poruchám. Tieto vlastnosti sú podrobne opísané nižšie
- Škálovateľná - Flume je škálovateľná horizontálne, tj môžeme podľa potreby pridať nové uzly
- Spoľahlivý - Apache Flume má podporu pre transakcie a zaisťuje, že v procese prenosu údajov sa nestratia žiadne údaje. Má rôzne transakcie od zdroja k kanálu a od kanála k zdroju.
- Flume je prispôsobiteľný a poskytuje podporu pre rôzne zdroje a drezy ako Kafka, Avro, spoolový adresár, Thrift atď.
- V službe Flume môže jediný zdroj prenášať údaje do viacerých kanálov a tieto kanály zase prenášajú údaje do viacerých umývadiel, takže jediný zdroj môže prenášať údaje do viacerých umývadiel. Tento mechanizmus sa nazýva Fan out. Flume tiež podporuje funkciu Fan out.
- Flume poskytuje stály tok prenosu údajov, tj ak sa zvyšuje rýchlosť čítania údajov a potom sa zvyšuje aj rýchlosť zápisu údajov.
- Aj keď služba Flume vo všeobecnosti zapisuje údaje do centralizovaného úložiska, napríklad HDFS alebo Hbase, môžeme nakonfigurovať službu Flume podľa našich požiadaviek tak, aby Sink mohla zapisovať údaje inému agentovi. To ukazuje flexibilitu Flume
- Apache Flume je v prírode open source.
záver
V tomto článku Flume sa podrobne diskutuje o zložkách Flume a jeho fungovaní. Flume je flexibilná, spoľahlivá a škálovateľná platforma na prenos údajov do centralizovaného obchodu, ako je HDFS. Vďaka svojej schopnosti integrovať sa s rôznymi aplikáciami, ako sú Kafka, Hdfs, Thrift, sa stáva životaschopnou možnosťou pre príjem dát.
Odporúčané články
Toto bol sprievodca Apache Flume. Tu diskutujeme o architektúre, fungovaní a výhodách Apache Flume. Ďalšie informácie nájdete aj v nasledujúcich článkoch -
- Čo je to Apache Flink?
- Rozdiel medzi Apache Kafka vs Flume
- Architektúra veľkých dát
- Hadoop Tools
- Naučte sa rôzne udalosti JavaScriptu