

Rozdiel medzi Hadoop a Hive
Hadoop:
Hadoop je rámec alebo softvér, ktorý bol vynájdený na správu obrovských údajov alebo veľkých dát. Hadoop sa používa na ukladanie a spracovanie veľkých dát distribuovaných cez klaster komoditných serverov.
Hadoop ukladá údaje pomocou distribuovaného systému súborov Hadoop a spracováva / dotazuje ich pomocou programovacieho modelu Map Reduce.
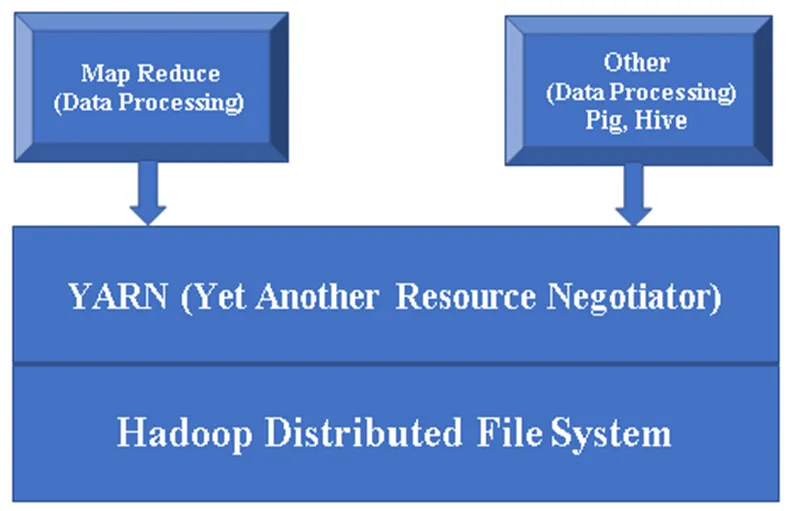
Obrázok 1, základná architektúra komponentu Hadoop.
Hlavné komponenty spoločnosti Hadoop:
Hadoop Base / Common: Hadoop common vám poskytne jednu platformu na inštaláciu všetkých jeho komponentov.
HDFS (Distribuovaný systém súborov Hadoop): HDFS je hlavnou súčasťou rámca Hadoop a stará sa o všetky údaje v Hadoop Cluster. Pracuje na architektúre Master / Slave a ukladá údaje pomocou replikácie.
Master / Slave Architecture & Replication:
- Hlavný uzol / názov uzla: Uzol názvu ukladá metadáta každého bloku / súboru uloženého v HDFS, HDFS môže mať iba jeden hlavný uzol (v prípade HA bude ďalší hlavný uzol fungovať ako sekundárny hlavný uzol).
- Uzol slave / dátový uzol: dátové uzly obsahujú skutočné dátové súbory v blokoch. HDFS môže mať viac dátových uzlov.
- Replikácia: HDFS ukladá svoje údaje ich rozdelením do blokov. Predvolená veľkosť bloku je 64 MB. Z dôvodu replikácie sa dáta ukladajú do 3 (predvolený replikačný faktor, možno zvýšiť podľa požiadavky), rôzne dátové uzly preto majú najmenšiu možnosť straty dát v prípade zlyhania uzla.
YARN (Yet Another Resource Negotiator): V zásade sa používa na správu zdrojov Hadoop, tiež hrá dôležitú úlohu pri plánovaní užívateľských aplikácií.
MR (Map Reduce): Toto je základný programovací model Hadoop. Používa sa na spracovanie / dotazovanie údajov v rámci Hadoop.
Úľ:
Hive je aplikácia, ktorá beží cez rámec Hadoop a poskytuje rozhranie podobné SQL na spracovanie / dotazovanie údajov. Úľ je navrhnutý a vyvinutý spoločnosťou Facebook predtým, ako sa stane súčasťou projektu Apache-Hadoop.
Hive spustí svoj dotaz pomocou HQL (jazyk dotazu Hive). Úľ má rovnakú štruktúru ako RDBMS a v Hive sa dajú použiť takmer rovnaké príkazy.
Úľ môže ukladať dáta do externých tabuliek, takže nie je povinné používať HDFS, ale tiež podporuje formáty súborov, ako sú ORC, Avro, Sequence File a Text súbory atď.
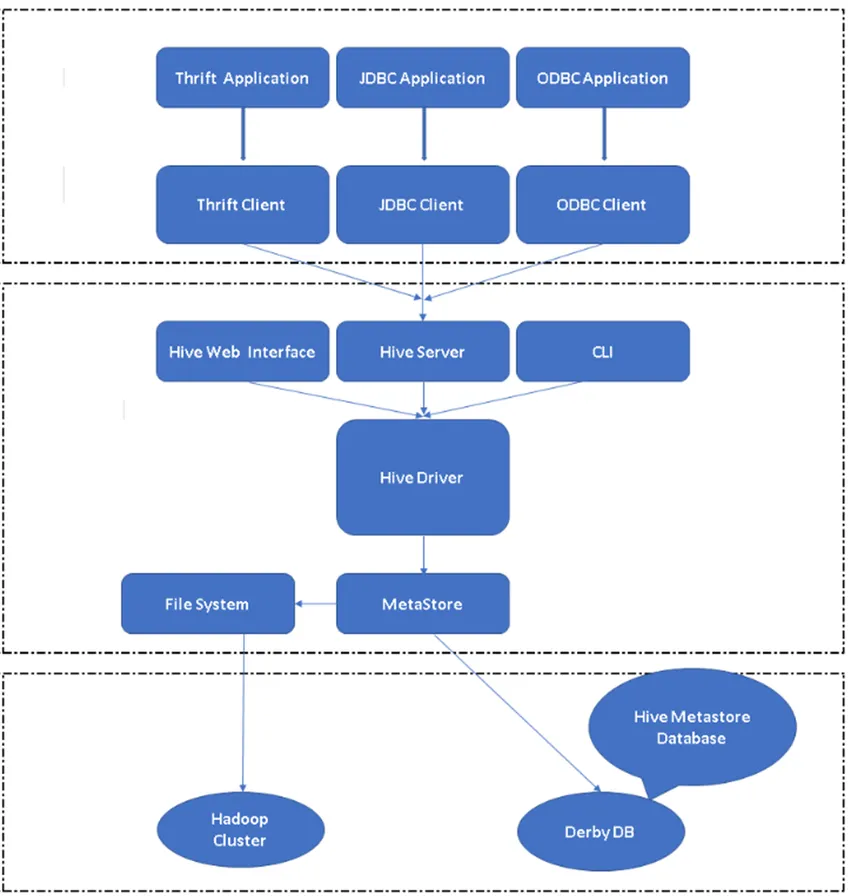
Obrázok 2, Architektúra Úľa a jeho hlavné komponenty.
Hlavný komponent úľa:
Hive Clients: Nielen SQL, Hive podporuje aj programovacie jazyky ako Java, C, Python pomocou rôznych ovládačov ako ODBC, JDBC a Thrift. Jeden môže písať ľubovoľnú klientskú aplikáciu v iných jazykoch a pomocou týchto klientov môže bežať v Úli.
Služby Úľa: V rámci služieb Úľa sa vykonáva vykonávanie príkazov a otázok. Webové rozhranie úľa má päť podzložiek.
- CLI: Predvolené rozhranie príkazového riadka poskytované Hive na vykonávanie dotazov / príkazov Hive.
- Hive Web Interfaces: Jedná sa o jednoduché grafické užívateľské rozhranie. Je to alternatíva k príkazovému riadku Hive a používa sa na spúšťanie otázok a príkazov v aplikácii Hive.
- Hive Server: Nazýva sa tiež Apache Thrift. Je zodpovedné prijímať príkazy z rôznych rozhraní príkazového riadku a posielať všetky príkazy / dotazy Úlu, ktorý tiež získava konečný výsledok.
- Ovládač Apache Hive: Je zodpovedný za prevzatie vstupov z rozhraní CLI, webového používateľského rozhrania, ODBC, JDBC alebo Thrift klientom a odovzdanie informácií metastore, kde sú uložené všetky informácie o súbore.
- Metastore: Metastore je úložisko na ukladanie všetkých informácií o metaúdajoch Úľa. Metadáta spoločnosti Hive uchovávajú informácie, ako je štruktúra tabuliek, oddielov a typu stĺpcov atď.…
Úľové úložisko: Je to miesto, kde sa vykonáva skutočná úloha. Všetky dotazy, ktoré sa spúšťajú z Úľa, vykonali akciu vnútri Úložného úložiska.
Porovnanie vzájomných vzťahov medzi Hadoopom a Úľom (infografika)
Nižšie je uvedený najlepší rozdiel medzi Hadoopom a Hive
Kľúčové rozdiely medzi Hadoopom a Hive:
Nižšie sú uvedené zoznamy bodov, opíšte kľúčové rozdiely medzi Hadoop a Hive:
1) Hadoop je rámec na spracovanie / dopytovanie veľkých dát, zatiaľ čo Hive je nástroj založený na SQL, ktorý stavia nad Hadoop na spracovanie údajov.
2) Spracovať / dotazovať všetky údaje pomocou HQL (Hive Query Language), je to jazyk podobný SQL, zatiaľ čo Hadoop dokáže porozumieť iba Map Reduce.
3) Mapa Reduce je neoddeliteľnou súčasťou Hadoop, Hiveho dotaz sa najskôr prevedie na Map Reduce, ako ho spracováva Hadoop na zisťovanie údajov.
4) Úľ pracuje na dotaze SQL Like, zatiaľ čo Hadoop to chápe iba pomocou mapového editora založeného na Java.
5) V Hive, predtým používané tradičné príkazy „Relational Database's“, sa dajú použiť aj na dotazovanie veľkých dát, zatiaľ čo v Hadoope je potrebné písať komplexné programy Map Reduce s použitím Java, ktorá nie je podobná tradičnej Java.
6) Úľ môže spracovávať / dotazovať len štruktúrované údaje, zatiaľ čo Hadoop je určený pre všetky typy údajov, či už sú štruktúrované, neštruktúrované alebo pološtrukturované.
7) Pomocou Úľa je možné spracovávať / dotazovať údaje bez zložitého programovania, zatiaľ čo v ekosystéme Simple Hadoop je potrebné pre rovnaké údaje napísať komplexný program Java.
8) Na jednej strane Hadoop frameworks potrebuje 100s linku na prípravu MR programu založeného na Java. Ďalšia strana Hadoop with Hive môže dotazovať rovnaké dáta pomocou 8 až 10 riadkov HQL.
9) V Hive je veľmi ťažké vložiť výstup jedného dotazu ako vstup druhého, zatiaľ čo ten istý dotaz sa dá ľahko vykonať pomocou Hadoop s MR.
10) Nie je povinné mať metastore v klastri Hadoop, zatiaľ čo Hadoop ukladá všetky svoje metadáta do HDFS (distribuovaný systém súborov Hadoop).
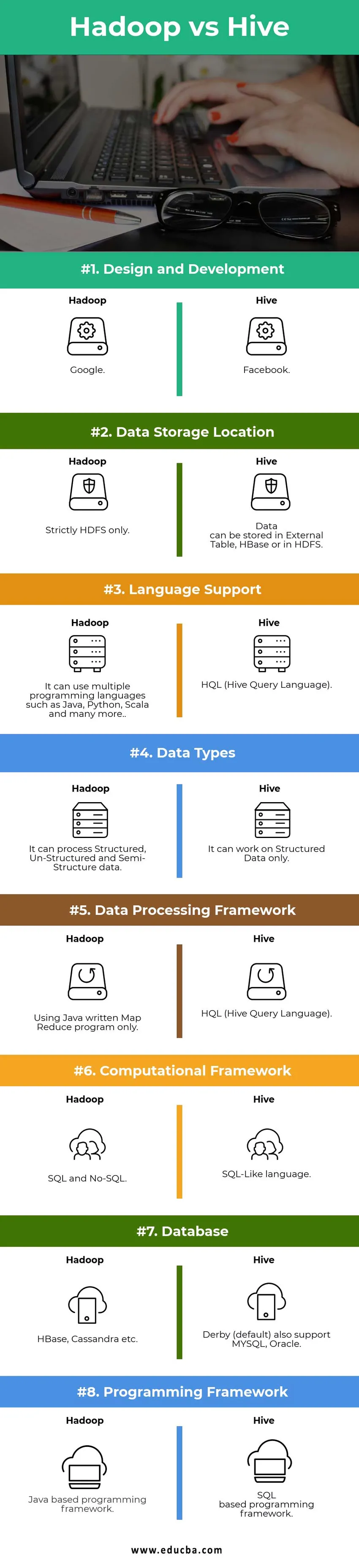
Porovnávacia tabuľka Hadoop vs Hive
| Porovnávacie body | Úľ | Hadoop |
|
Dizajn a vývoj | ||
| Miesto na uloženie údajov |
Dáta môžu byť uložené v externom formáte Tabuľka, HBase alebo v HDFS. | Iba prísne HDFS. |
| Jazyková podpora | HQL (jazyk dotazu úľa) |
Môže používať viacero programovacích jazykov ako Java, Python, Scala a mnoho ďalších. |
| Typy údajov | Môže fungovať iba na štruktúrovaných údajoch. |
Dokáže spracovať štruktúrované, neštruktúrované a pološtrukturované údaje. |
| Rámec spracovania údajov |
HQL (jazyk dotazu úľa) | Používa sa iba program Java Map Mapuce zapísaný v jazyku Java. |
|
Výpočtový rámec | Jazyk podobný jazyku SQL. | SQL a No-SQL. |
| databázy |
Derby (predvolené) tiež podporuje MYSQL, Oracle … | HBase, Cassandra atď. |
| Programovací rámec |
Programovací rámec založený na SQL. | Programovací rámec založený na Java. |
Záver - Hadoop vs Hive
Hadoop aj Hive sa používajú na spracovanie veľkých dát. Hadoop je rámec, ktorý poskytuje platformu pre ďalšie aplikácie na dopytovanie / spracovanie údajov Big Data, zatiaľ čo Hive je iba aplikácia založená na SQL, ktorá spracováva údaje pomocou HQL (Hive Query Language).
Hadoop sa dá použiť bez Hive na spracovanie veľkých dát, zatiaľ čo Hive bez Hadoop nie je ľahké používať.
Na záver nemôžeme porovnávať Hadoop a Hive v žiadnom prípade a v žiadnom aspekte. Hadoop aj Hive sú úplne odlišné. Spoločná prevádzka obidvoch technológií môže pre používateľov veľkých dát uľahčiť a uľahčiť proces dotazovania na veľké dáta.
Odporúčané články:
Toto bol návod pre Hadoop vs Hive, ich význam, porovnanie medzi dvoma hlavami, kľúčové rozdiely, porovnávacie tabuľky a závery. Ďalšie informácie nájdete aj v nasledujúcich článkoch -
- Hadoop vs Apache Spark - zaujímavé veci, ktoré potrebujete vedieť
- HADOOP vs RDBMS | Poznajte 12 užitočných rozdielov
- Ako veľké údaje menia tvár zdravotnej starostlivosti
- Top 12 Porovnanie Apache Hive vs Apache HBase (Infographics)
- Úžasný sprievodca Hadoop vs Spark