
Rozdiel medzi úľom a HBase
Apache Hive a HBase sú technológie veľkých dát založené na Hadoop. Obaja zvykli dotazovať údaje. Úľ a HBase bežia na vrchu Hadoopu a líšia sa svojou funkčnosťou. Hive je dialekt založený na SQL dialektoch, zatiaľ čo HBase podporuje iba MapReduce. HBase ukladá údaje vo forme párov kľúč / hodnota alebo stĺpec rodiny, zatiaľ čo Hive neukladá údaje.
Rozdiely Head to Head medzi Hive vs HBase (Infographics)
Nižšie je uvedený Top 8 Rozdiel medzi Úľom verzus HBase
Kľúčové rozdiely medzi Hive vs HBase
- Hbase vyhovuje ACID, zatiaľ čo Hive nie.
- Podregister podporuje rozdelenie a kritériá filtrovania založené na formáte dátumu, zatiaľ čo program HBase podporuje automatické rozdelenie na oddiely.
- Úľ nepodporuje aktualizačné vyhlásenia, zatiaľ čo HBase ich podporuje.
- Hbase je rýchlejší v porovnaní s Hive pri získavaní údajov.
- Úľ sa používa na spracovanie štruktúrovaných údajov, zatiaľ čo program HBase, pretože neobsahuje schému, môže spracovať akýkoľvek typ údajov.
- Hbase je vysoko (horizontálne) škálovateľná v porovnaní s Hive.
- Úľ analyzuje údaje na HDFS s podporou SQL Queries a potom ich prevedie na mapu a zníži počet úloh, zatiaľ čo v Hbase, keďže ide o streamovanie v reálnom čase, priamo vykonáva svoje operácie v databáze rozdelením na tabuľky a rodiny stĺpcov.
- keď prichádzame k dotazovaniu na dátový úľ, používa na vydávanie príkazov shell známy ako Hive shell, zatiaľ čo HBase, pretože ide o databázu, použijeme príkaz na spracovanie údajov v HBase.
- Na prechod do shellu úľa použijeme príkaz úľ. Potom, čo to dáte, bude to vyzerať ako úľ>. V HBase jednoducho dáme ako Use HBase.
Porovnávacia tabuľka Hive vs HBase
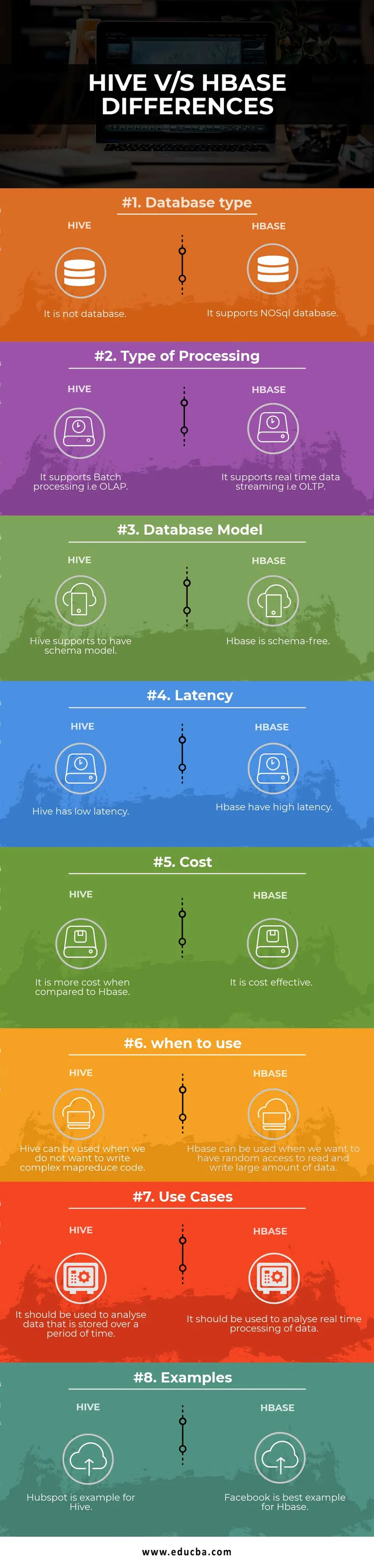
| Základ pre porovnanie | Úľ | Hbase |
| Typ databázy | Nejde o databázu | Podporuje databázu NoSQL |
| Druh spracovania | Podporuje dávkové spracovanie, tj OLAP | Podporuje streamovanie údajov v reálnom čase, tj OLTP |
| Databázový model | Podregister podporuje model schémy | Hbase neobsahuje schémy |
| latencia | Úľ má nízku latenciu | Hbase má vysokú latenciu |
| náklady | V porovnaní s HBase je to nákladnejšie | Je to nákladovo efektívne |
| kedy použiť | Úľ sa dá použiť, keď nechceme písať komplexný kód MapReduce | HBase sa dá použiť, keď chceme mať náhodný prístup na čítanie a zápis veľkého množstva údajov |
| Prípady použitia | Mal by sa používať na analýzu údajov, ktoré sa uchovávajú po určité časové obdobie | Mal by sa používať na analýzu spracovania údajov v reálnom čase. |
| Príklady | Hubspot je príkladom Úľa | Facebook je najlepším príkladom pre Hbase |
Rozdiely v kódovaní medzi Hive vs HBase
Poďme teraz diskutovať o základných rozdieloch medzi Hive a HBase v kódovaní.
| Základ pre porovnanie | Úľ | Hbase |
| Vytvorenie databázy | VYTVORIŤ DATABÁZU (POKIAĽ NIE SÚ) DATABÁZA - NÁZOV; | Pretože Hbase je databáza, nemusíme vytvárať konkrétnu databázu |
| Zrušenie databázy | DROP DATABÁZA (POKIAĽ IDE) DATABÁZA - MENO (OBMEDZENIE ALEBO CASCADE); | NA |
| Vytvorenie tabuľky | VYTVORIŤ (DOČASNÉ ALEBO VONKAJŠIE) TABUĽKY (AK NE EXISTUJÚ) TABUĽKA NÁZOV ((názov stĺpca-názov_dokumentu (stĺpec s komentárom-komentár), ….))) (tabuľka s komentárom-stĺpec) (formát riadku FORMÁT) (uložený ako formát súboru) | VYTVORIŤ „“, „“ |
| Zmena tabuľky | ALTER TABLE name RENAME TO new-name
ALTER TABLE name DROP (COLUMN) názov stĺpca ALTER TABLE name PRIDAŤ STĹPCE (col-spec (, col-spec ..)) ALTER TABLE name CHANGE column-name new-name new-type ALTER TABLE name REPLACE COLUMNS (col-spec (, col-spec ..)) | ALTER 'TABLE-NAME', NAME => 'COLUMN-NAME', VERSIONS => |
| Zakázanie tabuľky | NA | deaktivovať 'TABLE-NAME' -> na zakázanie zadaného názvu tabuľky
disable_all 'r *' -> na vypnutie všetkých tabuliek, ktoré sa zhodujú s regulárnym výrazom |
| Povolenie tabuľky | NA | povoliť „TABLE-NAME“ |
| Zrušenie tabuľky | TABUĽKA DROP AK EXISTUJE názov tabuľky | Ak chceme zrušiť tabuľku, najprv ju musíme vypnúť
zakázať 'table-name' drop 'table-name' Podobne môžeme použiť disable_all a drop_all na vymazanie tabuliek, ktoré zodpovedajú zadanému regulárnemu výrazu. |
| Zoznam databáz | Zobraziť databázy; | NA |
| Zoznam tabuliek v databáze | zobraziť tabuľky; | zoznam |
| Opísať schému tabuľky | opíšte názov tabuľky; | opíšte 'table-name' |
Integrácia úľa verzus HBase
- Nainštalujte a nakonfigurujte Úľ.
- Nainštalujte a nakonfigurujte program HBase.
- Na integráciu úľa a HBázy používame SKLADOVACIE MANIPULÁTORY v Úli.
- Handlery na ukladanie dát sú kombináciou SERDE, InputFormat a OutputFormat, ktorá akceptuje akúkoľvek externú entitu ako tabuľku v Úle.
- Táto funkcia teda pomáha užívateľovi vydávať dotazy SQL, či už je tabuľka prítomná v Hadoope alebo v databáze založenej na NOSQL, ako sú HBase, MongoDB, Cassandra, Amazon DynamoDB.
- Teraz sa pozrieme na jeden príklad prepojenia Hive s HBase pomocou HiveStorageHandler:
- Najprv musíme vytvoriť tabuľku Hbase pomocou príkazu.
vytvorte 'Student', 'personalinfo', 'dept info'
-> Personalinfo a dept info vytvárajú dve rôzne skupiny stĺpcov v tabuľke Student.
- Niektoré údaje musíme vložiť do tabuľky študentov. Napríklad, ako je uvedené nižšie.
uveďte 'student', 'sid01 ′, ' personalinfo: name ', ' Ram '
uveďte 'student', 'sid01 ′, ' personalinfo: mailid ', ' '
vložte 'student', 'sid01', 'deptinfo: deptname', 'Java'
uveďte 'Student', 'sid01', 'deptinfo: joinyear', '1994'
-> Podobne môžeme vytvoriť údaje pre sid02, sid03…
- Teraz musíme vytvoriť tabuľku Hive smerujúcu na tabuľku HBase.
- Pre každý stĺpec v Hbase vytvoríme jednu konkrétnu tabuľku pre tento stĺpec v Hive. V tomto prípade vytvoríme 2 tabuľky v Hive
create external table student_hbase(sid String, name String, mailid String)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler with serdeproperties("hbase.columns.mapping"=":key, personalinfo:name, personalinfo:mailid")
tblproperties("hbase.table.name"="student");
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
-> Podobne potrebujeme vytvoriť tabuľku s podrobnými informáciami o podrobnostiach v úli.
- Teraz môžeme napísať dotaz SQL do úľa, ako je uvedené nižšie.
select * from student_hbase;
Týmto spôsobom môžeme integrovať Hive s HBase.
Záver - Hive vs HBase
Ako už bolo uvedené, obidve sú odlišné technológie, ktoré poskytujú rôzne funkcie, v ktorých Hive pracuje pomocou jazyka SQL, a dá sa tiež nazvať ako HQL a HBase na analýzu údajov používajú páry kľúč - hodnota. Hive a HBase fungujú lepšie, ak sú kombinované, pretože Hive majú nízku latenciu a dokážu spracovať veľké množstvo údajov, ale nedokážu udržiavať aktuálne údaje a HBase nepodporuje analýzu údajov, ale podporuje aktualizácie na úrovni riadkov vo veľkom množstve. údajov.
Odporúčaný článok
Toto bol sprievodca Hive vs HBase, ich význam, porovnanie hlava-hlava, kľúčové rozdiely, porovnávacia tabuľka a záver. Ďalšie informácie nájdete aj v nasledujúcich článkoch -
- Apache Pig vs Apache Hive - Top 12 užitočných rozdielov
- Zistite 7 najlepších rozdielov medzi Hadoopom a HBase
- Top 12 Porovnanie Apache Hive vs Apache HBase (Infographics)
- Hadoop vs Hive - Zistite najlepšie rozdiely