

Rozdiel medzi Apache Hive a Apache HBase -
Príbeh Apache Hive sa začína v roku 2007, keď programátor Java nemá problémy s používaním aplikácie Hadoop MapReduce. Vedci a vývojári predpovedali, že zajtrajšia doba éry veľkých dát. Zhromažďovali sa už rôzne formáty údajov, ako sú štruktúrované, pološtrukturované a neštruktúrované. Dokonca aj Facebook zápasil s väčším množstvom spracovania údajov. Vedci na Facebooku predstavili Apache Hive pre spracovanie dát v Hadoop Cluster. Facebook bol prvou spoločnosťou, ktorá prišla s Apache Hive.
Príbeh Apache HBase sa začína v roku 2006, keď sa Powerset so spustením v San Franciscu snažil vytvoriť webový vyhľadávací stroj s prirodzeným jazykom. HBase je implementácia aplikácie Bigtable spoločnosti Google. Uvedomili sme si niekedy, prečo bolo potrebné prísť s ďalšou architektúrou úložiska? Systém správy relačných databáz existuje už od začiatku sedemdesiatych rokov. Existuje mnoho prípadov použitia, pre ktoré relačné databázy úplne dávajú zmysel, ale pre niektoré špecifické problémy sa relačný model veľmi dobre nehodí.
Dovoľte mi podrobnejšie vysvetliť informácie o Apache Hive a Apache HBase.
Rozdiely medzi Apache Hive a Apache HBase
Apache Hive je open-source projekt Apache postavený na vrchole Hadoopu na dotazovanie, sumarizáciu a analýzu veľkých súborov údajov pomocou rozhrania podobného SQL. Apache Hive poskytuje jazyk podobný SQL s názvom HiveQL, ktorý transparentne prevádza dotazy na MapReduce na vykonávanie na veľkých množinách údajov uložených v systéme Hadoop Distributed File System (HDFS). Apache Hive je komponent klastra Hadoop, ktorý bežne používajú analytici údajov. Úľ Apache sa používa na dávkové spracovanie veľkých úloh ETL. Apache Hive tiež podporuje dávkové dotazy SQL na veľmi veľké množiny údajov. Apache Hive zvyšuje flexibilitu pri návrhu schémy a tiež serializáciu a deserializáciu údajov. Apache Hive nepodporuje spracovanie online transakcií (OLTP), pretože úľ nepodporuje dotazy v reálnom čase a na úrovni riadkov.
Apache HBase je otvorená zdrojová databáza NoSQL, ktorá poskytuje prístup k veľkým súborom údajov v reálnom čase, na čítanie a zápis. NoSQL je nerelačná databáza. Apache HBase je distribuovaná stĺpcovo orientovaná databáza, ktorá beží nad Hadoop Distributed File System (HDFS). HBase prináša spoločnosti Hadoop výhody NoSQL. Apache HBase poskytuje možnosti náhodného prístupu k údajom prítomným v HDFS. Využíva toleranciu chýb poskytovanú HDFS. Užívateľ môže ukladať údaje v HDFS buď priamo, alebo prostredníctvom HBase.
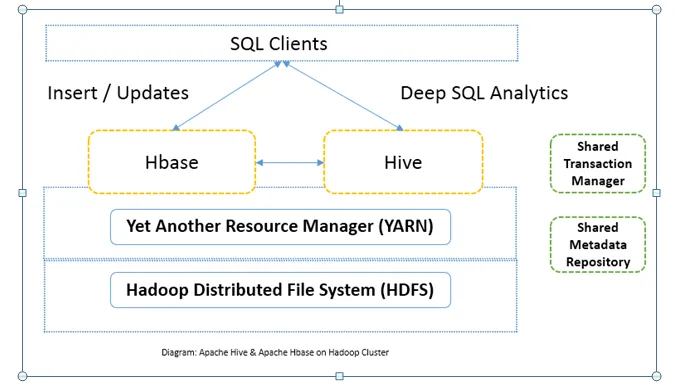
Porovnanie Head to Head medzi Apache Hive vs Apache HBase (Infographics)
Nižšie je uvedený 12 najlepších rozdielov medzi Apache Hive a Apache HBase

Kľúčové rozdiely - Apache Hive vs Apache HBase
Nižšie sú uvedené zoznamy bodov, opíšte kľúčové rozdiely medzi Apache Hive a Apache HBase:
- Apache HBase je databáza, zatiaľ čo Apache Hive je databázový stroj.
- Apache Hive sa používa hlavne na dávkové spracovanie (OLAP), zatiaľ čo Apache HBase sa používa hlavne na transakčné spracovanie (OLTP).
- Apache Hive vykonáva väčšinu dotazov SQL, zatiaľ čo Apache HBase neumožňuje dotazy SQL priamo.
- Apache Hive nepodporuje operácie na úrovni záznamu, ako je aktualizácia, vloženie a vymazanie, zatiaľ čo Apache HBase podporuje operácie na úrovni záznamu, ako je aktualizácia, vloženie a vymazanie.
- Apache Hive beží na MapReduce, zatiaľ čo Apache HBase beží na Hadoop Distributed File System (HDFS).
Apache Hive spytuje súbory definovaním virtuálnej tabuľky a spustením dotazov HQL nad ňou. Je to proces, v ktorom sú súbory virtuálne spojené s tabuľkou, ako je štruktúra, a používateľ môže spustiť Hive Query Language (HQL) a tieto dotazy sú konvertované do MapReduce Job by Hive. Užívateľ nemusí písať úlohu MapReduce, dotazy HQL sú interne konvertované do súborov jar a tieto súbory jar budú implementované do množín údajov.
V Apache HBase sú tabuľky rozdelené do regiónov a obsluhujú ich regionálne servery. Ďalšie oblasti sú vertikálne rozdelené stĺpcami do obchodov a obchody sa ukladajú ako súbory v HDFS.
Kedy používať Apache Hive:
- Požiadavky na skladovanie údajov
- Analytické otázky
- Analýza dát, ktorí sú oboznámení s SQL
Kedy použiť Apache HBase:
- Rýchle a interaktívne spracovanie údajov
- Dotazy v reálnom čase
- Rýchle vyhľadávanie
- Spracovanie na strane servera
- Náhodný prístup na čítanie / zápis do veľkých dát
- Škálovateľnosť aplikácií
Apache Hive sa dá použiť na výpočet trendov a protokolov webovej stránky elektronického obchodu pre konkrétne trvanie, región alebo časové pásmo. Môže byť použitý na spracovanie dávkového dotazu na historické údaje, zatiaľ čo Apache HBase môže byť používaný Facebookom alebo LinkedIn na zasielanie správ a analýzu v reálnom čase. Môže sa tiež použiť na počítanie hodnotení Páči sa mi.
Porovnávacia tabuľka Apache Hive vs Apache HBase
Diskutujem o hlavných artefaktoch a rozlišujem medzi Apache Hive a Apache HBase.
| Úľ Apache | Apache HBase | |
| Spracovanie dát | Apache Hive sa používa
dávkové spracovanie, tj online analytické spracovanie (OLAP) | Apache HBase sa používa na transakčné spracovanie, tj online transakčné spracovanie (OLTP) |
| Rýchlosť spracovania | Apache Hive má vyššiu latenciu kvôli vykonaniu úlohy MapReduce na pozadí | Apache HBase pracuje na dotazovaní v reálnom čase a oveľa rýchlejšie ako Apache Hive |
| Kompatibilita s Hadoop | Apache Hive beží na MapReduce | Apache HBase beží na vrchole HDFS |
| definícia | Apache Hive je open source a podobný SQL používanému pre analytické dotazy | Apache HBase je otvorená zdrojová databáza NoSQL používaná na dotazovanie v reálnom čase |
| Zdieľané metadáta | Údaje vytvorené v Apache Hive sú Apache HBase automaticky viditeľné | Údaje vytvorené v Apache HBase sú automaticky viditeľné pre Apache Hive |
| schéma | Podregister Apache podporuje schému na vkladanie údajov do tabuliek | Apache HBase je databáza bez schém. |
| Aktualizovať funkciu | Funkcia aktualizácie je v Apache Hive zložitá | Užívateľ môže veľmi ľahko aktualizovať dáta v Apache HBase |
| operácie | Operácie v Apache Hive nebeží v reálnom čase | Operácie v Apache HBase prebiehajú v reálnom čase |
| Typy údajov | Apache Hive je určený pre štruktúrované a pološtrukturované dáta | Apache HBase je určený pre neštruktúrované údaje. |
| Úroveň konzistencie | Úľ Apache podporuje prípadnú konzistenciu | Apache HBase podporuje okamžitú konzistenciu |
| Metódy rozdelenia | Apache Hive podporuje funkcie Sharding | Apache HBase tiež podporuje funkcie Sharding |
| Úložisko dát | Dátum je uložený v Hive Metastore, Partitions and Buckets v Apache Hive | Údaje sú uložené v stĺpcoch a riadkoch tabuliek v Apache HBase |
Záver - Apache Hive vs Apache HBase
Bežne sa Apache Hive verzus Apache HBase používa spolu v rovnakom klastri. Obidve môžu byť použité spolu na zvýšenie výkonu spracovania. Pretože úľ zlepšuje analytické stránky HDFS, zatiaľ čo HBase zlepšuje transakcie v reálnom čase. Užívateľ môže použiť Hive ako nástroj ETL na dávkové vkladanie údajov s údajmi do HBase a potom na vykonávanie dotazov, ktoré môžu ďalej spájať údaje prítomné v tabuľkách HBase s údajmi, ktoré už sú prítomné na HDFS. Dáta je možné čítať a zapisovať z Apache Hive do HBase a späť. Rozhranie medzi Apache Hive a Apache HBase je stále vo fáze zrenia. Je tu oveľa viac. Napriek tomu môžem povedať, že Apache Hive verzus Apache HBase robí cluster Hadoop robustnejším a výkonnejším.
Súvisiace články:
Toto bol návod pre Apache Hive verzus Apache HBase, ich význam, porovnanie hlava-hlava, kľúčové rozdiely, porovnávacia tabuľka a záver. Ďalšie informácie nájdete aj v nasledujúcich článkoch -
- Top 5 veľkých dátových trendov
- 5 Výzvy analýzy veľkých dát
- Ako rozlúštiť rozhovor pre vývojárov Hadoop?
- 5 Výzvy analýzy veľkých dát