

Rozdiel medzi Apache Nifi a Apache Spark
Až donedávna, keď bola ťažká práca, ktorú bolo potrebné dokončiť, sa ľudia spoliehali na kone, aby ťahali ťažké bremená, udržiavali rýchlosť alebo čokoľvek medzi tým. Nie všetky kone však boli vhodné na každú úlohu. To isté platí aj pre technológie dnes. S príchodom nových technológií, ktoré sa lejú každý deň, je mimoriadne dôležité poznať ich skutočné aplikácie. Dve takéto technológie sú Apache Nifi a Apache Spark a budeme o nich študovať v tomto príspevku.
Apache Spark je klastrový výpočtový open source framework, ktorého cieľom je poskytnúť rozhranie na programovanie celej sady klastrov s implicitnou odolnosťou proti chybám a paralelitou údajov. Využíva RDD (Resilient Distributed Datasets) a spracováva údaje vo forme diskrétnych tokov, ktoré sa ďalej využívajú na analytické účely.
Apache Nifi (čo je krátka forma NiagaraFiles) je ďalší softvérový projekt, ktorého cieľom je automatizovať tok dát medzi softvérovými systémami. Dizajn je založený na programovom modeli založenom na toku, ktorý poskytuje funkcie, ktoré zahŕňajú prácu so schopnosťou klastrov. Je to ľahko použiteľný, spoľahlivý a výkonný systém na spracovanie a distribúciu údajov. Podporuje škálovateľné riadené grafy pre smerovanie údajov, sprostredkovanie systému a logiku transformácie. Poďme diskutovať o porovnaní oboch tém.
Porovnanie medzi hlavami medzi Apache Nifi a Apache Spark (infografika)
Nižšie je najlepších 9 Porovnanie medzi Apache Nifi vs Apache Spark
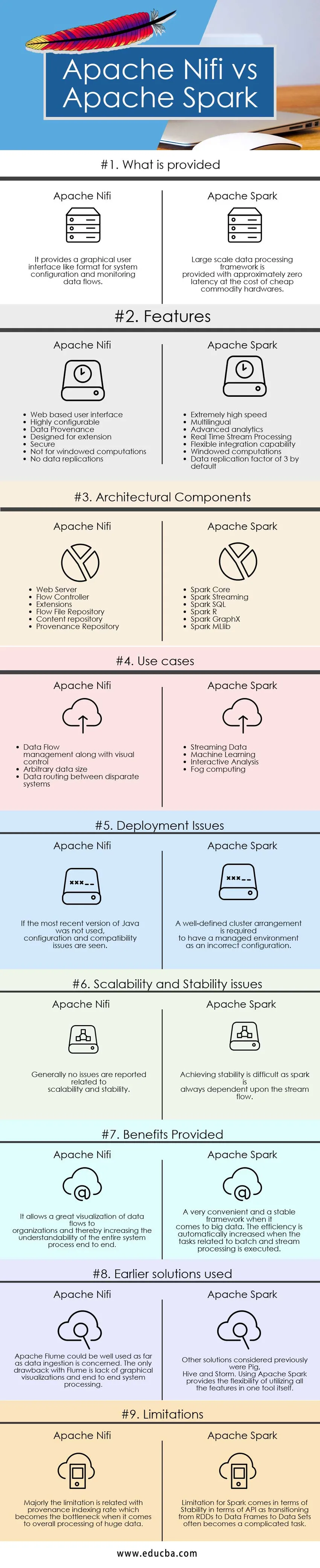
Kľúčové rozdiely medzi Apache Nifi a Apache Spark
Rozdiely medzi Apache Nifi a Apache Spark sú vysvetlené v nasledujúcich bodoch:
- Apache Nifi je nástroj na prijímanie údajov, ktorý sa používa na poskytovanie ľahko použiteľného, výkonného a spoľahlivého systému, takže spracovanie a distribúcia údajov cez prostriedky sa stáva ľahšou, zatiaľ čo Apache Spark je extrémne rýchla klastrová výpočtová technológia, ktorá je navrhnutá pre rýchlejšiu výpo efektívne využívanie interaktívnych otázok, v oblasti správy pamäte a spracovania toku.
- Apache Nifi pracuje v samostatnom režime a v klastrovom režime, zatiaľ čo Apache Spark funguje dobre v miestnom alebo samostatnom režime, Mesos, priadze a ďalších druhoch veľkých klastrov veľkých dát.
- Medzi vlastnosti Apache Nifi patrí zaručené dodávanie údajov, efektívne ukladanie údajov do vyrovnávacích pamätí, prioritné radenie do frontu, QoS špecifický pre tok, zabezpečenie dát, obnova vyrovnávacej pamäte, vizuálny príkaz a kontrola, šablóny toku, bezpečnosť, paralelné streamovanie, zatiaľ čo vlastnosti apache iskry zahŕňajú blesky rýchlo rýchlosť spracovania, viacjazyčné spracovanie, výpočty v pamäti, efektívne využívanie hardvérových komoditných systémov, pokročilá analytika, efektívne možnosti integrácie.
- Apache Nifi umožňuje lepšiu čitateľnosť a celkové porozumenie systému poskytovaním vizualizačných schopností a drag and drop funkcií. Tok údajov sa dá ľahko riadiť a riadiť pomocou konvenčných techník a procesov, zatiaľ čo v prípade Apache Spark je na zobrazenie týchto druhov vizualizácií potrebný systém riadenia klastrov, ako je Ambari. Samotný Apache Spark neposkytuje vizualizačné schopnosti a je dobrý len z hľadiska programovania. Je to zďaleka veľmi pohodlný a stabilný systém na spracovanie obrovského množstva údajov.
- Obmedzenie Apache Nifi súvisí s tým, čo je jeho výhodou. Jediná funkcia drag and drop poskytuje obmedzenie nemožnosti škálovať a poskytovať robustnosť, pokiaľ ide o jej integráciu s inými komponentmi a nástrojmi, zatiaľ čo v prípade Apache Spark primárne obmedzenie prichádza s použitím rozsiahleho komoditného hardvéru a jeho správou stáva sa občas únavou. Ďalšie hlásené obmedzenie prichádza spolu s jeho funkciami streamovania súvisiacimi s diskrétnym tokom a oknom alebo dávkovým tokom, kde transformácia RDD na dátový rámec a množiny údajov poskytuje občas príčinu nestability.
Porovnávacia tabuľka Apache Nifi vs Apache Spark
| Základ porovnania | Apache Nifi | Apache Spark |
| Čo je k dispozícii | Poskytuje grafické užívateľské rozhranie ako formát pre konfiguráciu systému a sledovanie dátových tokov. | Rámec rozsiahleho spracovania údajov je poskytovaný s približne nulovou latenciou za cenu lacného komoditného hardvéru. |
| Vlastnosti |
|
|
| Architektonické komponenty |
|
|
| Prípady použitia |
|
|
| Problémy s nasadením | Ak sa nepoužila najnovšia verzia Java, objavia sa problémy s konfiguráciou a kompatibilitou | Aby bolo spravované prostredie ako nesprávna konfigurácia, je potrebné správne definované usporiadanie klastrov |
| Problémy so škálovateľnosťou a stabilitou | Vo všeobecnosti sa neuvádzajú žiadne problémy súvisiace so škálovateľnosťou a stabilitou | Dosiahnutie stability je ťažké, pretože iskra je vždy závislá od toku prúdu. |
| Poskytnuté výhody | Umožňuje skvelú vizualizáciu tokov údajov do organizácií a tým zvyšuje zrozumiteľnosť celého procesu systému od začiatku do konca | Veľmi pohodlný a stabilný rámec, pokiaľ ide o veľké dáta. Účinnosť sa automaticky zvýši, keď sa vykonávajú úlohy súvisiace so spracovaním dávky a toku. |
| Použité predchádzajúce riešenia | Pokiaľ ide o príjem údajov, Apache Flume sa môže dobre využiť. Jedinou nevýhodou programu Flume je nedostatok grafických vizualizácií a spracovanie systému z jedného konca na druhý | Ďalšie riešenia, o ktorých sa predtým uvažovalo, boli ošípané, úľ a búrka. Použitie Apache Spark poskytuje flexibilitu pri využívaní všetkých funkcií v jednom samotnom nástroji. |
| obmedzenia | Obmedzenie sa týka hlavne miery indexácie proveniencie, ktorá sa stáva prekážkou, pokiaľ ide o celkové spracovanie obrovských údajov | Obmedzenie pre Spark prichádza z hľadiska stability z hľadiska API, pretože prechod z RDD na dátové rámce do množín údajov sa často stáva zložitou úlohou. |
Záver - Apache Nifi vs Apache Spark
Na záver príspevku je možné povedať, že Apache Spark je ťažký bojový kôň, zatiaľ čo Apache Nifi je úchvatný dostihový kôň. Obe majú svoje vlastné výhody a obmedzenia, ktoré sa majú použiť v ich príslušných oblastiach. Musíte sa rozhodnúť, ktorý nástroj je vhodný pre vaše podnikanie. Zostaňte naladení na náš blog, kde nájdete viac článkov týkajúcich sa novších technológií veľkých dát.
Odporúčaný článok
Toto bol sprievodca Apache Nifi verzus Apache Spark, ich význam, porovnanie hlava-hlava, kľúčové rozdiely, porovnávacia tabuľka a záver. Ďalšie informácie nájdete aj v nasledujúcich článkoch -
- Apache Hadoop vs Apache Spark | Top 10 porovnaní, ktoré musíte vedieť!
- Apache Storm vs Apache Spark - Naučte sa 15 užitočných rozdielov
- 7 dôležitých vecí o Apache Spark (Sprievodca)
- 15 najlepších vecí, ktoré potrebujete vedieť o MapReduce vs Spark