
Úvod do techniky súborov
Ensemble learning je technika strojového učenia, ktorá využíva niekoľko základných modelov a kombinuje ich výstup a vytvára optimalizovaný model. Tento typ algoritmu strojového učenia pomáha pri zlepšovaní celkového výkonu modelu. Základným modelom, ktorý sa najčastejšie používa, je klasifikátor stromov rozhodovania. Rozhodovací strom v podstate pracuje na niekoľkých pravidlách a poskytuje prediktívny výstup, kde sú pravidlami uzly a ich rozhodnutia budú ich deti a uzly listov budú predstavovať konečné rozhodnutie. Ako je znázornené na príklade rozhodovacieho stromu.
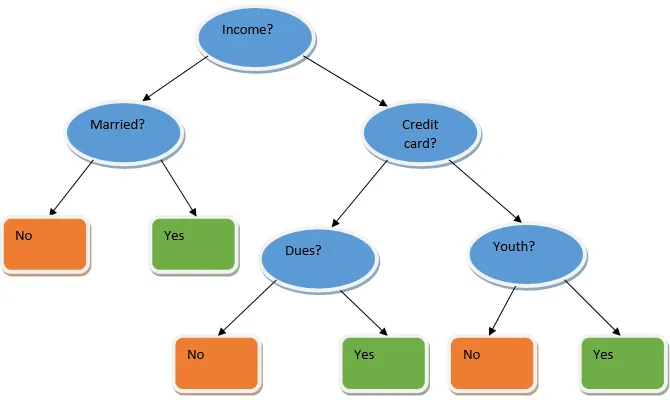
Vyššie uvedený rozhodovací strom v podstate hovorí o tom, či je možné osobe / zákazníkovi poskytnúť pôžičku alebo nie. Jedným z pravidiel pre oprávnenosť pôžičky áno je, že ak (príjem = Áno && Ženatý = Nie), potom pôžička = Áno, takže takto funguje klasifikátor rozhodovacích stromov. Tieto klasifikátory začleníme do viacerých základných modelov a skombinujeme ich výstupy tak, aby sme vytvorili jeden optimálny prediktívny model. Obrázok 1.b zobrazuje celkový obrázok algoritmu úplného učenia.
Typy techník súborov
Rôzne typy súborov, ale náš hlavný dôraz sa bude klásť na nižšie uvedené dva typy:
- vrecovanie
- posilňovanie
Tieto metódy pomáhajú znižovať odchýlky a skreslenie v modeli strojového učenia. Skúsme teraz pochopiť, čo je skreslenie a rozptyl. Predpojatosť je chyba, ktorá sa vyskytuje v dôsledku nesprávnych predpokladov v našom algoritme; vysoká zaujatosť naznačuje, že náš model je príliš jednoduchý / nevyhovujúci. Odchýlka je chyba, ktorá je spôsobená citlivosťou modelu na veľmi malé výkyvy v súbore údajov; veľká odchýlka naznačuje, že náš model je veľmi zložitý / nadmerne prispôsobený. Ideálny model ML by mal mať správnu rovnováhu medzi zaujatosťou a rozptylom.
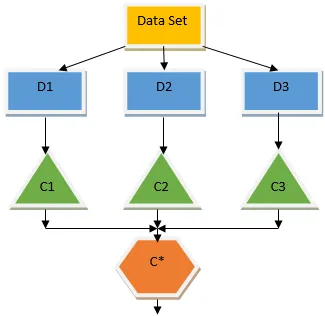
Agregácia / balenie batožinového priestoru
Bagging je kompletná technika, ktorá pomáha pri znižovaní rozptylu v našom modeli, a preto sa vyhýba nadmernému vybavovaniu. Bagging je príkladom algoritmu paralelného učenia. Sáčkovanie funguje na základe dvoch princípov.
- Bootstrapping: Z pôvodného súboru údajov sa uvažuje o nahradení rôznych vzoriek.
- Agregácia: Na účely spriemerovania výsledkov všetkých klasifikátorov a poskytnutia jediného výstupu používa na hlasovanie väčšinu v prípade klasifikácie a spriemerovanie v prípade regresného problému. Jedným zo známych algoritmov strojového učenia, ktoré používajú koncept vrecovania, je náhodný les.
Náhodný les
V náhodnom lese z náhodnej vzorky odobratej z populácie s nahradením a podmnožina prvkov je vybraná zo súboru všetkých prvkov, z ktorých je zostavený rozhodovací strom. Z týchto podmnožín funkcií sa vyberie ako koreň stromu rozhodovania ktorákoľvek funkcia, ktorá poskytuje najlepšie rozdelenie. Podmnožina prvkov musí byť vybraná náhodne za každú cenu, inak budeme nakoniec produkovať iba korelovaný tress a rozptyl modelu sa nezlepší.
Teraz sme zostavili náš model so vzorkami odobratými z populácie, otázkou je, ako tento model overíme? Keďže vzorky zvažujeme s náhradou, všetky vzorky sa nebudú brať do úvahy a niektoré z nich nebudú zahrnuté do žiadneho vrecka, preto sa nazývajú vzorky vzoriek. Môžeme overiť náš model pomocou týchto vzoriek OOB (z vrecka). Dôležitými parametrami, ktoré je potrebné brať do úvahy v náhodnom lese, je počet vzoriek a počet stromov. Uvažujme o „m“ ako o podmnožine funkcií a „p“ je celá sada funkcií, teraz je spravidla ideálne zvoliť si
- m as√a minimálna veľkosť uzla 1 ako problém klasifikácie.
- m ako P / 3 a minimálna veľkosť uzla 5 pre regresný problém.
M a p by sa mali považovať za parametre ladenia, keď sa zaoberáme praktickým problémom. Tréning môže byť ukončený, keď sa chyba OOB stabilizuje. Jednou nevýhodou náhodného lesa je to, že keď máme v našej množine údajov 100 funkcií a je dôležitých iba niekoľko funkcií, tento algoritmus bude mať slabý výkon.
posilňovanie
Boosting je algoritmus sekvenčného učenia, ktorý pomáha pri znižovaní zaujatosti v našom modeli a rozptylu v niektorých prípadoch učenia pod dohľadom. Pomáha tiež pri premene slabých študentov na silných študentov. Posilnenie funguje na princípe postupného umiestňovania slabých študentov a každému dátovému bodu pripisuje váhu po každom kole; väčšia váha je priradená chybne klasifikovaným údajovým bodom v predchádzajúcom kole. Táto postupná vážená metóda školenia nášho súboru údajov je kľúčovým rozdielom oproti spôsobu balenia.
Obr. 3a znázorňuje všeobecný prístup pri posilňovaní
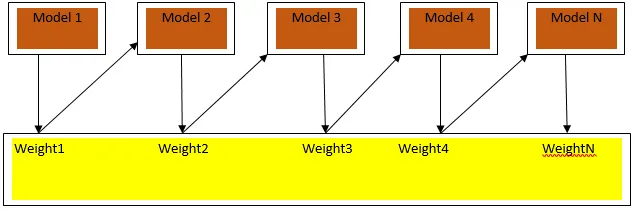
Konečné predpovede sa kombinujú na základe váženej väčšiny hlasov v prípade klasifikácie a váženej sumy v prípade regresie. Najčastejšie používaným zosilňovacím algoritmom je adaptívne zosilňovanie (Adaboost).
Adaptívne zvýšenie
Kroky zahrnuté v algoritme Adaboost sú nasledujúce:
- Pre dané n dátové body definujeme cieľovú nóbl a inicializujeme všetky váhy na 1 / n.
- Klasifikátory prispôsobíme množine údajov a vyberieme klasifikáciu s najmenšou váženou chybou klasifikácie
- Závažnosť klasifikátora priraďujeme palcovým pravidlom na základe presnosti, ak je presnosť vyššia ako 50%, potom je hmotnosť kladná a naopak.
- Na konci iterácie aktualizujeme váhy klasifikátorov; aktualizujeme väčšiu váhu pre nesprávne klasifikovaný bod, aby sme ho v nasledujúcej iterácii správne klasifikovali.
- Po každej iterácii získame konečný výsledok predpovede založený na väčšine hlasov / váženom priemere.
Adaboosting efektívne pracuje so slabými (menej zložitými) žiakmi as vysoko klasifikovanými klasifikátormi. Hlavnými výhodami Adaboostingu je to, že je rýchly, neexistujú žiadne ladiace parametre podobné prípadu baggingu a slabým žiakom nerobíme žiadne predpoklady. Táto technika neposkytne presný výsledok, keď
- V našich údajoch je viac odľahlých hodnôt.
- Súbor údajov je nedostatočný.
- Slabí študenti sú veľmi komplexní.
Sú tiež citlivé na hluk. Rozhodovacie stromy, ktoré sa vyrábajú v dôsledku zosilnenia, budú mať obmedzenú hĺbku a vysokú presnosť.
záver
Pri zlepšovaní presnosti modelu sa široko používajú techniky učenia sa súboru; musíme sa rozhodnúť, ktorú techniku použijeme na základe nášho súboru údajov. Tieto techniky však nie sú uprednostňované v niektorých prípadoch, keď je dôležitá interpretovateľnosť, pretože stratíme interpretovateľnosť na úkor zlepšenia výkonu. Majú obrovský význam v zdravotníckom priemysle, kde je veľmi cenné malé zlepšenie výkonnosti.
Odporúčané články
Toto je sprievodca technikami súboru. Tu diskutujeme úvod a dva hlavné typy techník súboru. Viac informácií nájdete aj v ďalších súvisiacich článkoch.
- Steganografické techniky
- Techniky strojového učenia
- Techniky budovania tímu
- Algoritmy vedy o údajoch
- Najpoužívanejšie techniky ensemble learningu