

Úvod do lineárnej regresnej analýzy
Je často mätúce naučiť sa nejaký koncept, ktorý je dokonca súčasťou nášho každodenného života. To však nie je problém, môžeme si pomôcť a rozvíjať sa, aby sme sa poučili z našich každodenných aktivít len analýzou vecí a nebojíme sa kladenia otázok. Prečo cena ovplyvňuje dopyt po tovare, prečo zmena úrokovej sadzby ovplyvňuje ponuku peňazí. Na všetky tieto otázky možno odpovedať jednoduchým prístupom známym ako lineárna regresia. Jedinou zložitosťou, ktorú pociťujeme pri riešení lineárnej regresnej analýzy, je identifikácia závislých a nezávislých premenných.
Musíme zistiť, čo má vplyv a polovica problému je vyriešená. Musíme zistiť, či to ovplyvňuje správanie sa cena alebo dopyt. Keď sme sa dozvedeli, ktorá z nich je nezávislá premenná a závislá premenná, je dobré ísť do našej analýzy. K dispozícii je niekoľko typov regresnej analýzy. Táto analýza závisí od premenných, ktoré máme k dispozícii.
3 typy regresnej analýzy
Tieto tri regresné analýzy majú prípady maximálneho použitia v reálnom svete, inak existuje viac ako 15 druhov regresnej analýzy. Typy regresnej analýzy, o ktorých budeme diskutovať, sú:
- Lineárna regresná analýza
- Analýza viacnásobnej lineárnej regresie
- Logistická regresia
V tomto článku sa zameriame na jednoduchú lineárnu regresnú analýzu. Táto analýza nám pomáha identifikovať vzťah medzi nezávislým a závislým faktorom. Zjednodušene povedané, model regresie nám pomáha zistiť, ako zmeny nezávislého faktora ovplyvňujú závislý faktor. Tento model nám pomáha niekoľkými spôsobmi, napríklad:
- Je to jednoduchý a výkonný štatistický model
- Pomôže nám to pri vytváraní predpovedí a predpovedí
- Pomôže nám to urobiť lepšie obchodné rozhodnutie
- Pomôže nám to analyzovať výsledky a opraviť chyby
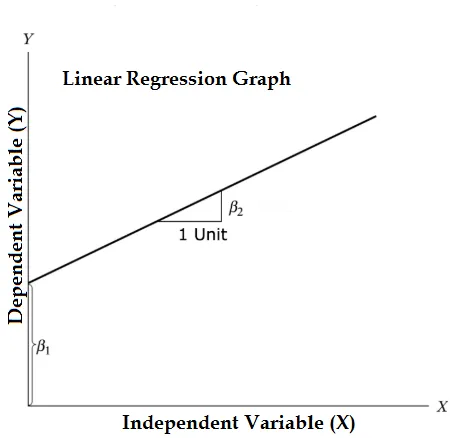
Rovnica lineárnej regresie a rozdelená na relevantné časti
Y = P1 + P2X + ϵ
- Kde β1 v matematickej terminológii známej ako zastavenie a β2 v matematickej terminológii známej ako sklon. Sú známe aj ako regresné koeficienty. ϵ je chybový termín, je súčasťou Y, ktorú regresný model nedokáže vysvetliť.
- Y je závislá premenná (iné termíny, ktoré sa vzájomne používajú pre závislé premenné, sú premenná odozvy, regresná veličina, meraná premenná, pozorovaná premenná, reagujúca premenná, vysvetlená premenná, výsledná premenná, experimentálna premenná a / alebo výstupná premenná).
- X je nezávislá premenná (regresory, riadená premenná, manipulovala s premennou, vysvetľujúcou premennou, expozičnou premennou a / alebo vstupnou premennou).
Problém: Pre pochopenie toho, čo je lineárna regresná analýza, berieme dataset „Cars“, ktorý je štandardne dodávaný v R adresároch. V tomto súbore údajov je 50 pozorovaní (v podstate riadkov) a 2 premenné (stĺpce). Názvy stĺpcov sú „Dist“ a „Speed“. Tu musíme vidieť vplyv na premenné vzdialenosti kvôli zmenám rýchlostných premenných. Pre zobrazenie štruktúry údajov môžeme spustiť kód Str (dataset). Tento kód nám pomáha pochopiť štruktúru súboru údajov. Tieto funkcie nám pomáhajú robiť lepšie rozhodnutia, pretože máme lepšiu predstavu o štruktúre súboru údajov. Tento kód nám pomáha určiť typ množiny údajov.
kód:

Podobne na kontrolu štatistických kontrolných bodov v súbore údajov môžeme použiť kód Summary (automobily). Tento kód poskytuje stredný, stredný rozsah dátového súboru za sebou, ktorý môže výskumný pracovník použiť pri riešení problému.
Výkon:
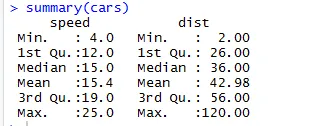
Tu vidíme štatistický výstup každej premennej, ktorú máme v našom súbore údajov.
Grafické znázornenie súborov údajov
Typy grafického znázornenia, ktoré tu nájdete, sú a prečo:
- Bodový graf: Pomocou grafu vidíme, ktorým smerom sa náš lineárny regresný model uberá, či existuje nejaký silný dôkaz, ktorý by náš model dokázal alebo nie.
- Box Plot: Pomáha nám pri hľadaní odľahlých hodnôt.
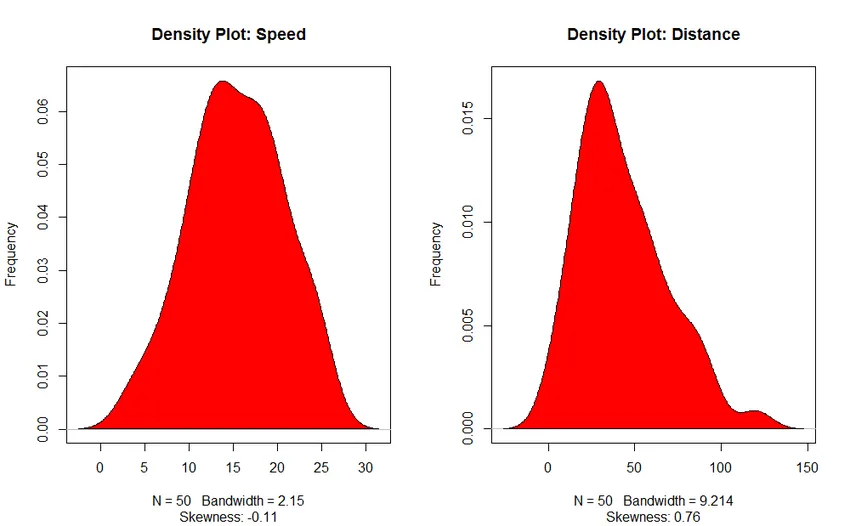
- Density Plot: Pomôžte nám pochopiť distribúciu nezávislej premennej, v našom prípade je nezávislou premennou „rýchlosť“.
Výhody grafického znázornenia
Tu sú nasledujúce výhody:
- Ľahko pochopiteľné
- Pomáha nám rýchlo sa rozhodnúť
- Porovnávacia analýza
- Menej úsilia a času
1. Bodový graf: Pomôže si vizualizovať akékoľvek vzťahy medzi nezávislou premennou a závislou premennou.
kód:

Výkon:
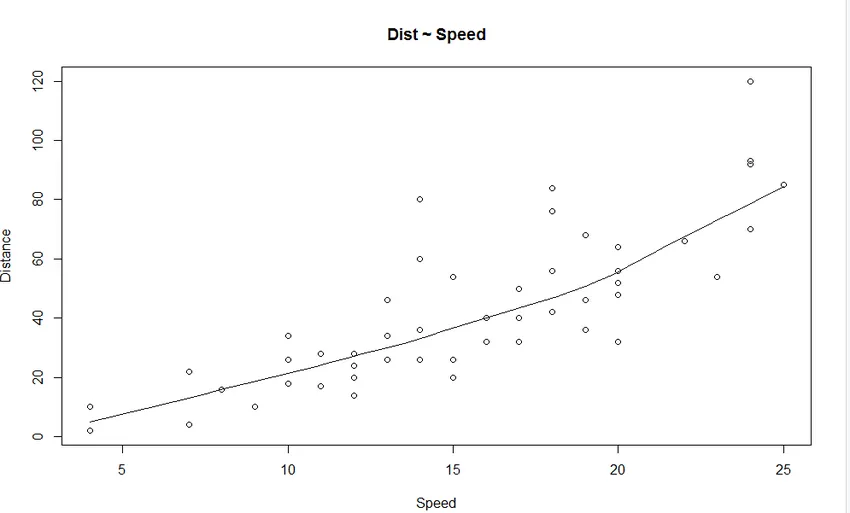
Z grafu vidíme lineárne rastúci vzťah medzi závislou premennou (vzdialenosť) a nezávislou premennou (rýchlosť).
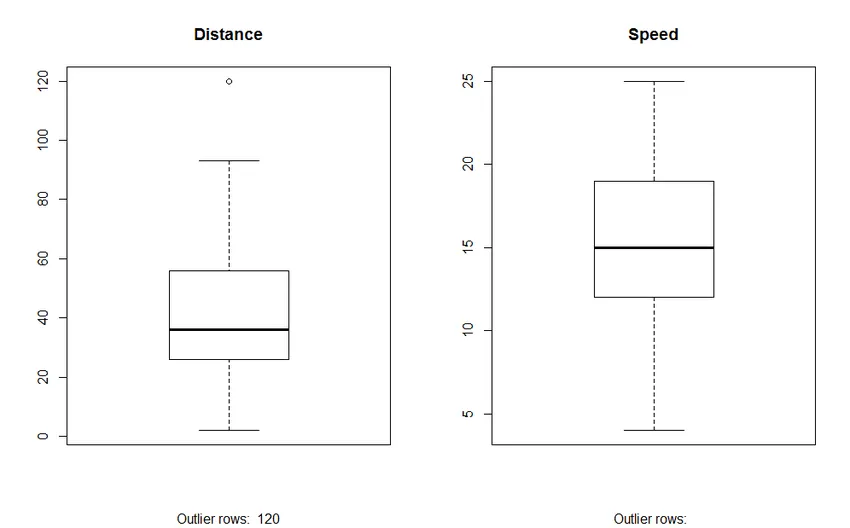
2. Box Plot: Box plot nám pomáha identifikovať odľahlé hodnoty v množinách údajov. Výhody použitia grafu v rámčeku sú:
- Grafické zobrazenie umiestnenia a šírenia premenných.
- Pomáha nám to pochopiť skewness a symetriu údajov.
kód:

Výkon:
3. Plot hustoty (na kontrolu normality distribúcie)
kód:
 Výkon:
Výkon:
Korelačná analýza
Táto analýza nám pomáha nájsť vzťah medzi premennými. Existuje hlavne šesť typov korelačnej analýzy.
- Pozitívna korelácia (0, 01 až 0, 99)
- Záporná korelácia (-0, 99 až -0, 01)
- Žiadna korelácia
- Dokonalá korelácia
- Silná korelácia (hodnota bližšia ± 0, 99)
- Slabá korelácia (hodnota bližšia k 0)
Bodový graf nám pomáha zistiť, ktoré typy korelačných dátových súborov majú medzi nimi a kód na nájdenie korelácie je

Výkon:
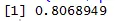
Tu máme silnú pozitívnu koreláciu medzi rýchlosťou a vzdialenosťou, čo znamená, že medzi nimi existuje priamy vzťah.
Lineárny regresný model
Toto je základná súčasť analýzy, predtým sme sa snažili a skúšali veci, či máme dataset, ktorý je dostatočne logický na to, aby sme mohli takúto analýzu spustiť alebo nie. Funkcia, ktorú plánujeme použiť, je lm (). Táto funkcia obsahuje dva prvky, ktoré sú vzorec a dáta. Pred priradením toho, ktorá premenná je závislá alebo nezávislá, si musíme byť veľmi istí, pretože od toho závisí celý náš vzorec.
Vzorec vyzerá takto:
Lineárna regresia <- lm (závislá premenná ~ nezávislá premenná, dáta = Date.Frame)
kód:

Výkon:
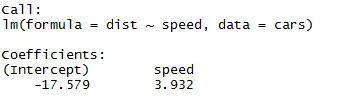
Ako môžeme spomenúť z vyššie uvedeného segmentu článku, rovnica lineárnej regresie je:
Y = P1 + P2X + ϵ
Teraz sa do tejto rovnice zmestia informácie, ktoré sme dostali z vyššie uvedeného kódu.
vzdialenosť = -17, 579 + 3, 932 ∗ rýchlosť
Iba nájsť rovnicu lineárnej regresie nestačí, musíme tiež skontrolovať jej štatistickú významnosť. Z tohto dôvodu musíme na našom modeli lineárnej regresie odovzdať kód „Zhrnutie“.
kód:

Výkon:

Existuje niekoľko spôsobov, ako skontrolovať štatistickú významnosť modelu, tu používame metódu P-hodnota. Model považujeme za štatisticky vhodný, keď je hodnota P menšia ako vopred stanovená štatisticky významná hladina, ktorá je ideálne 0, 05. V tabuľke zhrnutia (lineárna regresia) vidíme, že hodnota P je pod úrovňou 0, 05, takže môžeme konštatovať, že náš model je štatisticky významný. Keď sme si istí, o našom modeli, môžeme použiť náš súbor údajov na predpovedanie vecí.
Odporúčané články
Toto je sprievodca analýzou lineárnej regresie. Tu diskutujeme tri typy lineárnej regresnej analýzy, grafické znázornenie datasetov s výhodami a modely lineárnej regresie. Viac informácií nájdete aj v ďalších súvisiacich článkoch.
- Regresná formule
- Regresné testovanie
- Lineárna regresia v R
- Typy techník analýzy údajov
- Čo je to regresná analýza?
- Hlavné rozdiely regresie v porovnaní s klasifikáciou
- 6 najväčších rozdielov lineárnej regresie v porovnaní s logistickou regresiou