
Úvod do režimu dlhodobého spánku
Existujú rôzne vzťahy, ktoré udržujeme, aby sme vytvorili vzťahy medzi rôznymi databázovými tabuľkami v relačných databázových modeloch. Tieto vzťahy sú jeden ku každému, jeden k mnohým a veľa k mnohým. Podobný koncept sa inštaluje v režime dlhodobého spánku. Hibernate tu pracuje na prepojení jazyka JAVA s databázovou tabuľkou a týmto odkazom môžeme nadviazať vzťahy / mapovania. Tieto mapovania sa môžu použiť na navigáciu v databáze. Toto mapovanie je definované v hárku XML. Toto je všeobecne napísané programátormi, ale na jeho vytvorenie sa môžu použiť aj rôzne nástroje. Niektoré z týchto nástrojov sú XDoclet, AndroMDA a Middlegen.
Primárne typy mapovania dlhodobého spánku
Existujú predovšetkým tri typy mapovania. Sú to tieto:
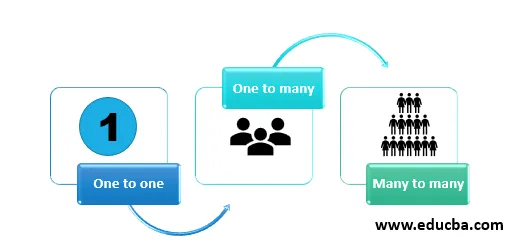
- Jeden ku každému: V tomto druhu vzťahu je jeden atribút mapovaný na iný atribút takým spôsobom, že je zachované iba jedno mapovanie jedného. Toto je možné lepšie pochopiť pomocou príkladu. Napríklad, ak jedna osoba pracuje iba pre jedno oddelenie. Tá istá osoba nemôže byť zamestnaná na inom oddelení, potom sa toto mapovanie nazýva jedna ku druhej.
- Jeden k mnohým: V tomto druhu vzťahu je jeden atribút mapovaný na iný atribút takým spôsobom, že jeden atribút je mapovaný na mnoho ďalších atribútov. Toto je možné lepšie pochopiť pomocou príkladu. Napríklad: Ak je jeden študent členom rôznych skupín. Rovnako ako kultúrna skupina, športový klub, robotický klub súčasne. V takom prípade sa vzťah medzi študentom a skupinou nazýva vzťahom mnoho k jednému.
- Mnoho k mnohým: V tomto druhu vzťahu je jeden atribút mapovaný na iný atribút takým spôsobom, že ľubovoľný počet atribútov môže byť spojený s inými atribútmi bez obmedzenia počtu. Toto je možné lepšie pochopiť pomocou príkladu. Napríklad: V knižnici môže jedna osoba vziať viac kníh a jednu knihu môže vydať do viacerých kníh. Tento druh vzťahu sa nazýva mnoho k mnohým vzťahom. Toto je komplexný vzťah a pred implementáciou je potrebné veľa porozumieť prípadu použitia v podniku.
Podrobné vysvetlenie režimu dlhodobého spánku
Ak prejdeme kódom, pochopíme, že v databáze je vytvorená tabuľka EMP_ATTR, ktorá ukladá atribúty zamestnancov, ktoré majú stĺpce ako meno, priezvisko a plat. Dáta z java aplikácie sú uložené v tejto tabuľke, ktorá je vyvinutá na klientskom rozhraní.
Technická špecifikácia založená na kóde napísanom na vysvetlenie:
je koreňový uzol, ktorý obsahuje prvky. Trieda sa používa na prepojenie javy s databázou pomocou dvoch atribútov. Názov triedy „emp“ je názov triedy prevzatý z kódu java, zatiaľ čo tabuľka „EMP_ATTR“ je názov tabuľky z databázy. element help pri mapovaní primárneho kľúča na jedinečné ID.
Primárny kľúč je v databáze, zatiaľ čo jedinečné ID sú odvodené od triedy java. názov pochádza z javy, zatiaľ čo stĺpec je stĺpec z tabuľky v databáze. Atribút type má štýl mapovania dlhodobého spánku, ktorý prevádza typ údajov java na typ údajov sql. trieda sa používa na automatické generovanie primárneho kľúča. Prvok generátora je „natívny“.
To dáva indikáciu pre hibernáciu, že môže vybrať ľubovoľný navrhnutý algoritmus, ako je Hilo, algoritmus identity alebo sekvencie, na vytvorenie primárneho kľúča. Nakoniec trieda. Toto je definujúca trieda, ktorá mapuje vlastnosť triedy java na stĺpec v tabuľke databázy. Atribút name sa týka názvu vlastnosti triedy java, zatiaľ čo stĺpec je stĺpec z tabuľky v databáze. Atribút type obsahuje typ hibernácie, ktorý pomôže systému určiť typ údajov pri konverzii údajov triedy java na typ údajov RDBMS (systém správy relačných databáz).
Poznámka: Toto je kód na vysvetlenie režimu dlhodobého spánku. Nejde o skutočnú implementáciu kódu.kód:
Takto vyzerá súbor XML. Pochádza z hibernate.org, čo je oficiálna webová stránka Hibernate.
"-//Hibernate/Hibernate Mapping DTD//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
"-//Hibernate/Hibernate Mapping DTD//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
"-//Hibernate/Hibernate Mapping DTD//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
Tento súbor sa uloží vo formáte .hbm.xml. V takom prípade by mal byť súbor uložený na meno EMP_ATR.hbm.xml.
Typ mapovania dlhodobého spánku
Takže v predchádzajúcom príklade kódu vidíme typy mapovania dlhodobého spánku v súbore XML. Tieto typy mapovania môžu byť mnohých typov:
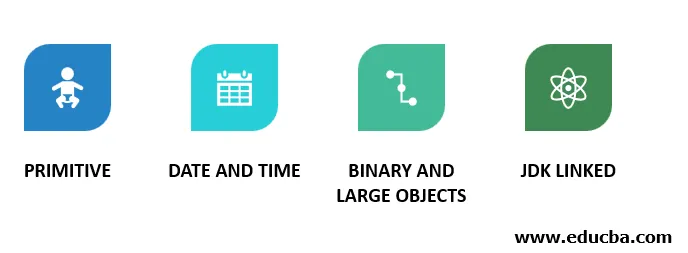
- Primitívne: Tieto typy mapovania majú dátové typy definované ako „celé číslo“, „znak“, „plavák“, „reťazec“, „dvojitý“, „booleovský“, „krátky“, „dlhý“ atď. mapovať dátový typ Java na dátový typ RDBMS.
- Dátum a čas: Sú to „dátum“, „čas“, „kalendár“, „časová pečiatka“ atď. Rovnako ako primitívne máme aj tieto mapovania dátových a dátumových údajov.
- Binárne a veľké objekty: Tieto typy sú „clob“, „blob“, „binary“, „text“ atď. Existujú typy údajov Clob a blob na zachovanie mapovania typov údajov veľkých objektov, ako sú obrázky a videá.
- Prepojené JDK: Niektoré mapovania objektov, ktoré sa nachádzajú mimo dosahu predchádzajúcich typov mapovaní, sú zahrnuté v tejto kategórii. Sú to „trieda“, „miestne nastavenie“, „mena“, „časové pásmo“.
záver
Preto je mapovanie dlhodobého spánku koncepciou, ktorú je možné realizovať vytvorením mapovaní pomocou súborov XML. Tieto mapovania sa stanú základom databázy navrhnutej podľa požiadaviek obchodného modelu. Pomáha to pri určovaní vzťahov medzi perzistentnými objektmi v databáze. Toto mapovanie je rozhodujúce pre návrh databázy, pretože sa stáva základom aplikácie front-end z hľadiska výkonu, presnosti a rýchlosti.
Odporúčané články
Toto je sprievodca Hibernate Mapping. Tu diskutujeme o dlhodobom mapovaní s podrobným vysvetlením, typmi a primárnymi typmi dlhodobého mapovania spolu so vzorovým kódom. Viac informácií nájdete aj v nasledujúcom článku -
- Čo je režim dlhodobého spánku?
- Režim dlhodobého spánku
- Čo je to Java Hibernate?
- Hibernate Interview Otázky