
Úvod do Poissonovej regresie v R
Poissonova regresia je typ regresie, ktorá je podobná viacnásobnej lineárnej regresii s tou výnimkou, že odozva alebo závislá premenná (Y) sú početné. Závislá premenná nasleduje Poissonovo rozdelenie. Prediktor alebo nezávislé premenné môžu mať charakter spojitý alebo kategorický. Svojím spôsobom je podobný logistickej regresii, ktorá má aj diskrétnu premennú odozvy. Predchádzajúce pochopenie Poissonovho rozdelenia a jeho matematickej formy je veľmi dôležité, aby sa využilo na predpoveď. V R sa Poissonova regresia môže implementovať veľmi účinným spôsobom. R ponúka komplexnú sadu funkcií na jeho implementáciu.
Implementácia Poissonovej regresie
Teraz pochopíme, ako sa model používa. V nasledujúcej časti je uvedený postup krok za krokom. Pre túto demonštráciu uvažujeme o „gala“ dátovom súbore z „vzdialeného“ balíka. Týka sa druhovej diverzity na Galapágskych ostrovoch. V súbore údajov je celkom 7 premenných. Poissonovu regresiu použijeme na definovanie vzťahu medzi počtom druhov rastlín (druh) s inými premennými v súbore údajov.
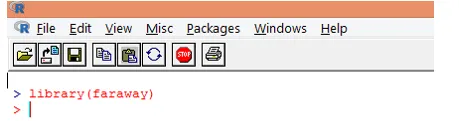
1. Najskôr vložte balík „ďaleko“. V prípade, že balík nie je k dispozícii, stiahnite ho pomocou funkcie install.packages ().
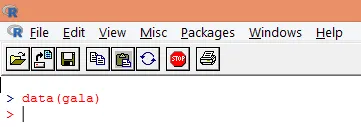
2. Akonáhle sa balík načíta, vložte „gala“ súbor údajov do R pomocou funkcie data (), ako je uvedené nižšie.
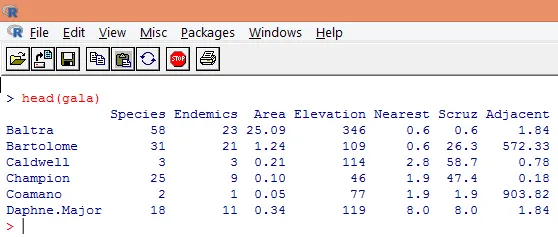
3. Načítané údaje by sa mali vizualizovať, aby sa študovala premenná a overilo sa, či existujú nejaké nezrovnalosti. Pomocou funkcie head (), ako je to znázornené na nasledujúcom snímke obrazovky, si môžeme vizualizovať buď celé údaje, alebo iba ich prvých niekoľko riadkov.
4. Ak chcete získať podrobnejší prehľad o súbore údajov, môžeme použiť funkciu pomoci v R, ako je uvedené nižšie. Generuje dokumentáciu R, ako je znázornené na snímke obrazovky po snímke nižšie.


5. Ak študujeme súbor údajov, ako je uvedené v predchádzajúcich krokoch, potom zistíme, že druh je premenná odozvy. Teraz si preštudujeme základné zhrnutie prediktorových premenných.
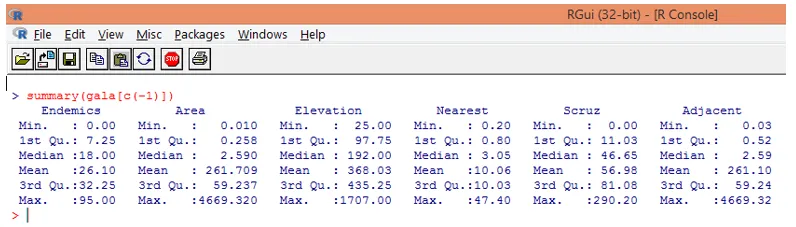
Ako je vidieť vyššie, vylúčili sme premennú Druh. Zhrnutie funkcie nám dáva základné informácie. Len sledujte stredné hodnoty pre každú z týchto premenných a zistíme, že medzi prvou polovicou a druhou polovicou existuje obrovský rozdiel, pokiaľ ide o rozsah hodnôt, napr. Stredná hodnota pre premennú oblasti je 2, 59, ale maximum hodnota je 4669, 320.
6. Teraz, keď sme hotoví so základnou analýzou, vygenerujeme histogram pre druh, aby sme skontrolovali, či premenná nasleduje poissonovské rozdelenie. Toto je znázornené nižšie.

Vyššie uvedený kód generuje histogram premennej Druh spolu s krivkou hustoty nad ňou.
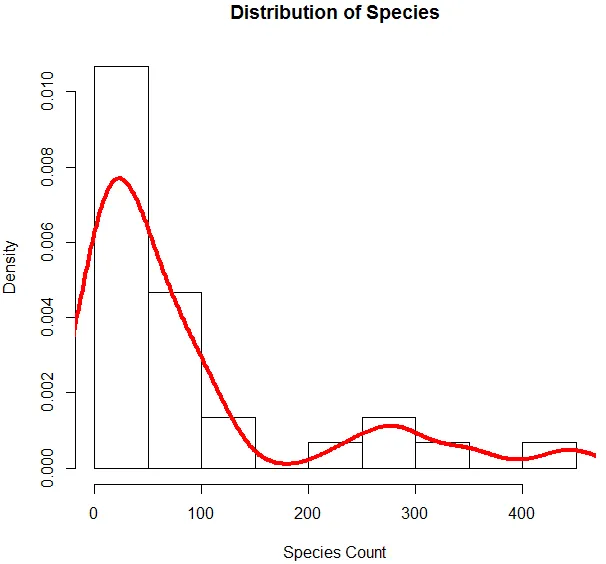
Vyššie uvedená vizualizácia ukazuje, že druh sleduje Poissonovo rozdelenie, pretože údaje sú správne zošikmené. Môžeme vygenerovať aj boxplot, aby sme získali lepší prehľad o distribučnom modeli, ako je uvedené nižšie.
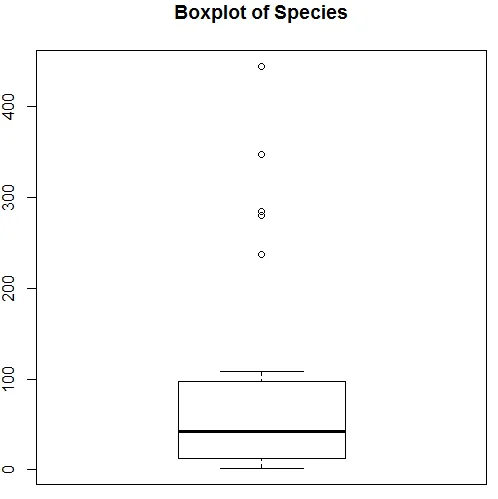
7. Po vykonaní predbežnej analýzy teraz použijeme Poissonovu regresiu, ako je uvedené nižšie
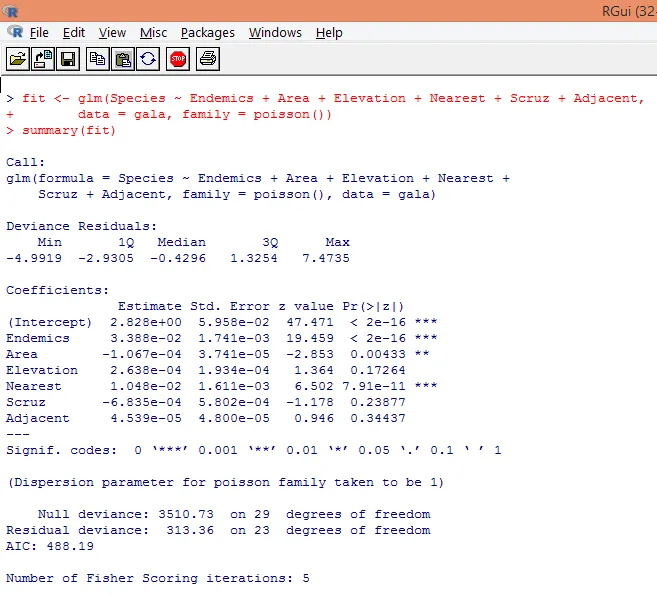
Na základe vyššie uvedenej analýzy sme zistili, že premenné Endemics, Area a Nearest sú významné a iba ich začlenenie postačuje na vytvorenie správneho Poissonovho regresného modelu.
8. Postavíme modifikovaný Poissonov regresný model, ktorý bude brať do úvahy iba tri premenné. Endemika, oblasť a najbližšie. Pozrime sa, aké výsledky dosiahneme.
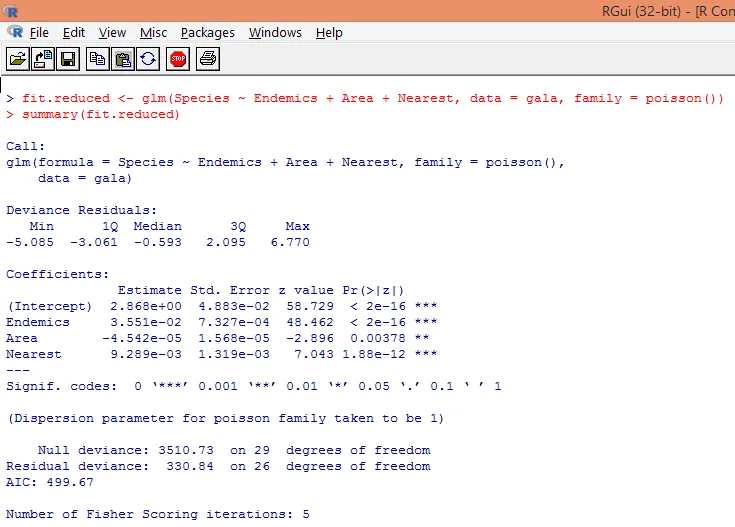
Výstup produkuje odchýlky, regresné parametre a štandardné chyby. Vidíme, že každý z parametrov je významný na úrovni p <0, 05.
9. Ďalším krokom je interpretácia parametrov modelu. Modelové koeficienty možno získať buď preskúmaním koeficientov vo vyššie uvedenom výstupe alebo pomocou funkcie coef ().
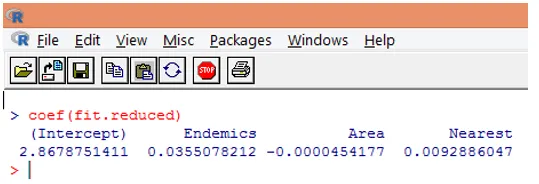
V Poissonovej regresii je závislá premenná modelovaná ako log podmieneného priemerného loge (l). Regresný parameter 0, 0355 pre Endemics naznačuje, že zvýšenie o jednu jednotku v premennej je spojené so zvýšením o 0, 04 v priemernom počte druhov druhov, zatiaľ čo ostatné premenné zostávajú konštantné. Priesečník predstavuje logaritmus stredného počtu druhov, keď sa každý z prediktorov rovná nule.
10. Je však oveľa ľahšie interpretovať regresné koeficienty v pôvodnej mierke závislej premennej (počet druhov, a nie log-číslo druhov). Vyčlenenie koeficientov umožní ľahkú interpretáciu. Toto sa vykonáva nasledujúcim spôsobom.
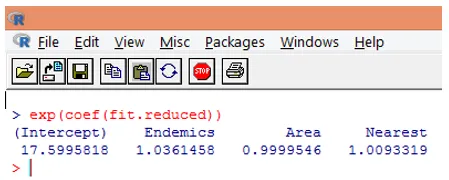
Z vyššie uvedených zistení je možné konštatovať, že jedno zvýšenie jednotky v oblasti znásobuje očakávaný počet druhov o 0, 9999 a zvýšenie počtu endemických druhov zastúpených endemikami vynásobí počet druhov o 1, 0361. Najdôležitejším aspektom Poissonovej regresie je to, že exponentované parametre majú skôr multiplikačný ako aditívny účinok na premennú odozvy.
11. Pomocou vyššie uvedených krokov sme získali Poissonov regresný model na predpovedanie počtu rastlinných druhov na Galapágskych ostrovoch. Je však veľmi dôležité skontrolovať nadmernú disperziu. V Poissonovej regresii sú rozptyl a prostriedky rovnaké.
K nadmernej disperzii dochádza, keď je pozorovaná odchýlka premennej odozvy väčšia, ako by sa dalo predpovedať Poissonovou distribúciou. Analýza nadmernej disperzie sa stáva dôležitou, pretože je bežná v prípade údajov o počte a môže mať negatívny vplyv na konečné výsledky. V R možno nadmernú disperziu analyzovať pomocou balíka „qcc“. Analýza je ilustrovaná nižšie.
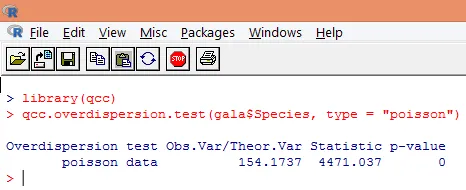
Vyššie uvedený významný test ukazuje, že hodnota p je menšia ako 0, 05, čo silne naznačuje prítomnosť nadmernej disperzie. Pokúsime sa namontovať model pomocou funkcie glm () nahradením family = “Poisson” s family = “quasipoisson”. Toto je znázornené nižšie.
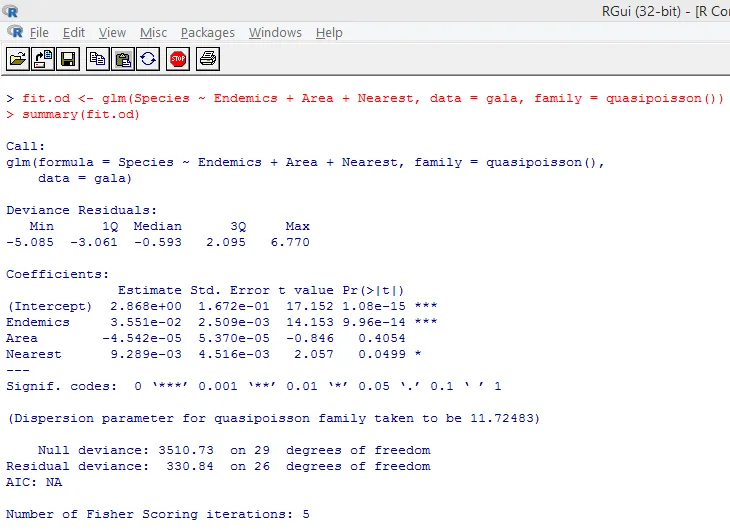
Pri podrobnom štúdiu vyššie uvedeného výstupu vidíme, že odhady parametrov v kvázi-Poissonovom prístupe sú totožné s odhadmi vytvorenými prístupom Poisson, hoci štandardné chyby sa líšia pre oba prístupy. Okrem toho v tomto prípade je pre oblasť p-hodnota vyššia ako 0, 05, čo je spôsobené väčšou štandardnou chybou.
Dôležitosť Poissonovej regresie
- Poissonova regresia v R je užitočná pre správne predpovede diskrétnej / počítacej premennej.
- Pomáha nám to identifikovať tie vysvetľujúce premenné, ktoré majú štatisticky významný vplyv na premennú odozvy.
- Poissonova regresia v R je najvhodnejšia pre udalosti „zriedkavej“ povahy, pretože majú tendenciu sledovať Poissonovu distribúciu v porovnaní s bežnými udalosťami, ktoré zvyčajne sledujú normálnu distribúciu.
- Je vhodný na použitie v prípadoch, keď je premenná odozvy malé celé číslo.
- Má široké uplatnenie, keďže v mnohých situáciách je rozhodujúca predpoveď diskrétnych premenných. V medicíne sa môže použiť na predpovedanie vplyvu lieku na zdravie. Používa sa pri analýze prežitia, ako je smrť biologických organizmov, zlyhanie mechanických systémov atď.
záver
Poissonova regresia je založená na koncepcii Poissonovej distribúcie. Je to ďalšia kategória patriaca do súboru regresných techník, ktorá kombinuje vlastnosti lineárnej aj logistickej regresie. Na rozdiel od Logistickej regresie, ktorá generuje iba binárny výstup, sa však používa na predpovedanie diskrétnej premennej.
Odporúčané články
Toto je sprievodca poissonovskou regresiou v R. Tu diskutujeme o úvode Implementácia Poissonovej regresie a význam Poissonovej regresie. Viac informácií nájdete aj v ďalších navrhovaných článkoch -
- GLM v R.
- Generátor náhodných čísel v R
- Regresná formule
- Logistická regresia v R
- Lineárna regresia vs logistická regresia Hlavné rozdiely