

Úvod do techniky vedy o údajoch
V dnešnom svete, v ktorom sú údaje novým zlatom, existujú rôzne druhy analýz, ktoré môže podnik urobiť. Výsledok projektu vedy o údajoch sa veľmi líši v závislosti od typu dostupných údajov, a preto je vplyv takisto premenlivý. Pretože je k dispozícii veľa rôznych druhov analýz, je nevyhnutné porozumieť tomu, čo je potrebné vybrať z niekoľkých základných techník. Základným cieľom techník vedy o údajoch je nielen hľadanie relevantných informácií, ale aj odhalenie slabých väzieb, ktoré majú tendenciu zhoršovať výkonnosť modelu.
Čo je to Data Science?
Dáta veda je oblasť, ktorá sa šíri cez niekoľko disciplín. Zahŕňa vedecké metódy, procesy, algoritmy a systémy na zhromažďovanie poznatkov a prácu na nich. Táto oblasť zahŕňa rôzne žánre a predstavuje spoločnú platformu pre zjednotenie pojmov štatistika, analýza údajov a strojové učenie. Teoretické znalosti štatistík spolu s údajmi a technikami v reálnom čase v strojovom vzdelávaní sú ruka v ruke s cieľom dospieť k plodným výsledkom pre podnikanie. Použitím rôznych techník používaných vo vede údajov môžeme my v dnešnom svete naznačiť lepšie rozhodovanie, ktoré by inak mohlo zmeškať ľudské oko a myseľ. Pamätajte, že stroj nikdy nezabudne! Aby sa maximalizoval zisk vo svete založenom na údajoch, je nevyhnutným nástrojom kúzlo Data Science.
Rôzne typy dátovej techniky
V nasledujúcich niekoľkých odsekoch by sme sa zaoberali bežnými technikami vedy o údajoch, ktoré sa používajú v každom ďalšom projekte. Aj keď niekedy môže byť technika dátovej vedy špecifická pre obchodné problémy a nemusí spadať do nižšie uvedených kategórií, je úplne v poriadku ich označiť ako rôzne typy. Na vysokej úrovni rozdelíme techniky na supervízované (vieme cieľový dopad) a nedohľadnuté (nevieme o cieľovej premennej, ktorú sa snažíme dosiahnuť). V ďalšej úrovni je možné techniky rozdeliť na
- Výstup, ktorý by sme dostali, alebo aký je zámer obchodného problému
- Druh použitých údajov.
Pozrime sa najprv na segregáciu založenú na úmysle.
1. Výučba bez dozoru
- Detekcia anomálie
Pri tomto type techniky identifikujeme akýkoľvek neočakávaný výskyt v celom súbore údajov. Keďže sa správanie líši od skutočného výskytu údajov, predpoklady sú tieto:
- Počet týchto prípadov je veľmi malý.
- Rozdiel v správaní je významný.
Vysvetľujú sa algoritmy anomálií, ako je napríklad Isolation Forest, ktorý poskytuje skóre pre každý záznam v množine údajov. Tento algoritmus je stromový model. Použitím tohto typu detekčnej techniky a jej popularity sa používajú v rôznych obchodných prípadoch, napríklad pri zobrazovaní webových stránok, miere odlivu, výnosoch za kliknutie atď. V nasledujúcom grafe môžeme vysvetliť, ako anomálie vyzerá.
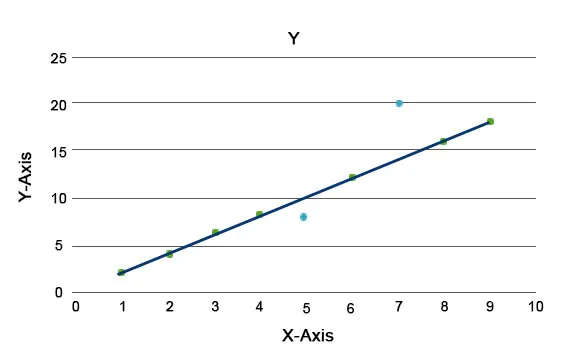
Modré tu predstavujú anomáliu v súbore údajov. Líšia sa od bežnej trendovej čiary a vyskytujú sa menej.
- Zhluková analýza
Hlavnou úlohou tejto analýzy je rozdeliť celý súbor údajov do skupín tak, aby trend alebo vlastnosti v jednej skupine údajov boli navzájom veľmi podobné. V terminológii vedy o údajoch ich nazývame klaster. Napríklad v maloobchode existuje plán na rozšírenie rozsahu podnikania a je nevyhnutné vedieť, ako sa budú noví zákazníci správať v novom regióne na základe minulých údajov, ktoré máme. Je nemožné navrhnúť stratégiu pre každého jednotlivca v populácii, ale bude užitočné zhromaždiť obyvateľstvo do zhlukov tak, aby stratégia bola účinná v skupine a bola škálovateľná.
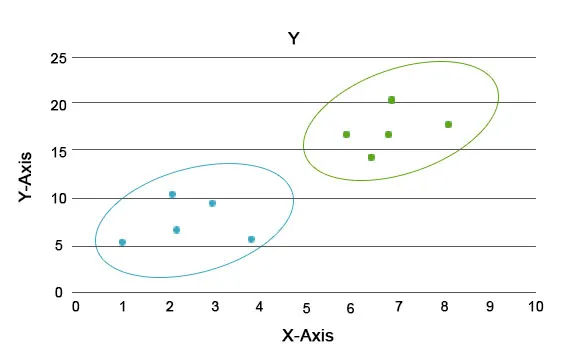
Modré a oranžové farby sú tu rôzne zhluky, ktoré majú v sebe jedinečné vlastnosti.
- Analýza asociácie
Táto analýza nám pomáha pri budovaní zaujímavých vzťahov medzi položkami v súbore údajov. Táto analýza odhaľuje skryté vzťahy a pomáha pri reprezentácii položiek súboru údajov vo forme pravidiel priradenia alebo súborov častých položiek. Pravidlo priradenia je rozdelené do dvoch krokov:
- Generovanie častých položiek: V tomto prípade sa generuje množina, v ktorej sa často vytvárajú často sa vyskytujúce položky.
- Generovanie pravidiel: Vyššie uvedená zostava prechádza rôznymi vrstvami tvorby pravidiel, aby sa medzi nimi vytvoril skrytý vzťah. Sada môže napríklad spadať do koncepčných alebo implementačných problémov alebo do aplikačných problémov. Tieto sa potom rozvetvujú do príslušných stromov, aby sa vytvorili pravidlá priradenia.
Napríklad APRIORI je algoritmus vytvárania asociačných pravidiel.
2. Dozorované učenie
- Regresná analýza
V regresnej analýze definujeme závislú / cieľovú premennú a zostávajúce premenné ako nezávislé premenné a nakoniec predpokladáme, ako jedna alebo viac nezávislých premenných ovplyvňuje cieľovú premennú. Regresia s jednou nezávislou premennou sa nazýva univariate a s viac ako jednou sa nazýva multivariate. Porozumejme používaniu univariate a potom mierky pre multivariate.
Napríklad y je cieľová premenná a x 1 je nezávislá premenná. Z poznania priamky môžeme rovnicu napísať ako y = mx 1 + c. Tu „m“ určuje, ako silne je y ovplyvnené x 1 . Ak je „m“ veľmi blízko nule, znamená to, že pri zmene x 1 nie je y silne ovplyvnené. Pri čísle väčšom ako 1 sa vplyv zosilnie a malá zmena v x 1 vedie k veľkej variabilite v y. Podobne ako pri univariate, v multivariate možno písať ako y = m 1 x 1 + m 2 x 2 + m 3 x 3 ………., Tu je vplyv každej nezávislej premennej určený jej zodpovedajúcim „m“.
- Klasifikačná analýza
Podobne ako pri zhlukovej analýze sa vytvárajú klasifikačné algoritmy, ktoré majú cieľovú premennú vo forme tried. Rozdiel medzi klastrovaním a klasifikáciou spočíva v tom, že pri klastrovaní nevieme, do ktorej skupiny spadajú údajové body, zatiaľ čo v klasifikácii vieme, do ktorej skupiny patrí. Od regresie sa líši tým, že počet skupín by mal byť na rozdiel od regresie stály počet, je nepretržitý. V klasifikačnej analýze existuje veľa algoritmov, napríklad podporné vektorové stroje, logistická regresia, rozhodovacie stromy atď.
záver
Na záver pochopíme, že každý druh analýzy je sám o sebe obrovský, ale tu môžeme poskytnúť malú príchuť rôznym technikám. V nasledujúcich niekoľkých poznámkach by sme každú z nich zobrali osobitne a podrobne rozobrali rôzne subtechniky použité v každej rodičovskej technike.
Odporúčaný článok
Toto je príručka k technikám Data Science. Diskutujeme o úvode a rôznych druhoch techník vo vede. Viac informácií nájdete aj v ďalších navrhovaných článkoch -
- Nástroje na vedu o údajoch 12 najlepších nástrojov
- Algoritmy vedy o údajoch s typmi
- Úvod do kariéry vedeckých údajov
- Data Science vs Vizualizácia dát
- Príklady viacrozmernej regresie
- Vytvorte rozhodovací strom s výhodami
- Stručný prehľad životného cyklu údajov