

Úvod do ťažby dát
Toto je metóda získavania údajov, ktorá sa používa na umiestňovanie dátových prvkov do ich podobných skupín. Klaster je postup rozdelenia dátových objektov do podtried. Kvalita klastrov závisí od použitej metódy. Zhlukovanie sa nazýva aj segmentácia údajov, pretože veľké skupiny údajov sa delia podľa ich podobnosti.
Čo je zoskupovanie v ťažbe údajov?
Klastrovanie je zoskupenie konkrétnych objektov na základe ich charakteristík a ich podobností. Pokiaľ ide o dolovanie údajov, táto metodika rozdeľuje údaje, ktoré sú najvhodnejšie pre požadovanú analýzu, pomocou špeciálneho algoritmu spojenia. Táto analýza umožňuje, aby objekt nebol súčasťou alebo prísne súčasťou klastra, ktorý sa nazýva tvrdé rozdelenie tohto typu. Hladké oddiely však naznačujú, že každý objekt v rovnakej miere patrí do klastra. Špecifickejšie divízie môžu byť vytvorené ako objekty viacerých klastrov, môže byť nútený sa zúčastniť jeden klaster alebo sa môžu v skupinových vzťahoch vytvárať aj hierarchické stromy. Tento súborový systém môže byť zavedený rôznymi spôsobmi na základe rôznych modelov. Tieto odlišné algoritmy sa vzťahujú na každý model, pričom sa rozlišujú ich vlastnosti a výsledky. Dobrý klastrovací algoritmus je schopný identifikovať klaster nezávisle od tvaru klastra. Existujú 3 základné fázy klastrovacieho algoritmu, ktoré sú uvedené nižšie
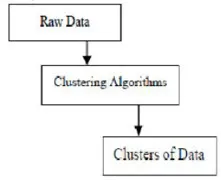
Klastrovacie algoritmy pri ťažbe dát
V závislosti od nedávno opísaných klastrových modelov sa môže veľa klastrov použiť na rozdelenie informácií na skupinu údajov. Malo by sa povedať, že každá metóda má svoje výhody a nevýhody. Výber algoritmu závisí od vlastností a charakteru súboru údajov.
Metódy zhlukovania na dolovanie údajov môžu byť uvedené nižšie
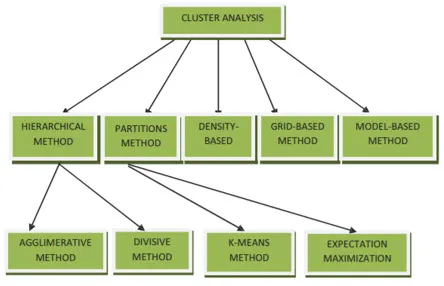
- Metóda založená na rozdelení
- Metóda založená na hustote
- Metóda založená na ťažkostiach
- Hierarchická metóda
- Metóda založená na mriežke
- Metóda založená na modeli
1. Metóda založená na rozdelení na oddiely
Algoritmus oddielu rozdeľuje údaje do mnohých podmnožín.
Predpokladajme, že algoritmus rozdelenia vytvára oddiel údajov, keďže k a n sú objekty v databáze. Preto bude každý oddiel reprezentovaný ako k ≤ n.
Toto dáva predstavu, že klasifikácia údajov je v skupinách k, čo je uvedené nižšie
Obrázok 1 zobrazuje pôvodné body zoskupovania

Obrázok 2 zobrazuje zoskupovanie oddielov po použití algoritmu
To znamená, že každá skupina má aspoň jeden objekt a každý objekt musí patriť do jednej skupiny.
2. Metóda založená na hustote
Tieto algoritmy vytvárajú zhluky na určenom mieste na základe vysokej hustoty účastníkov súboru údajov. Agreguje určitú predstavu rozsahu pre členov skupiny v zoskupeniach na štandardnú úroveň hustoty. Takéto procesy môžu pri zisťovaní povrchových plôch skupiny viesť menej.
3. Metóda založená na ťažisku
Takmer na každý zo zhlukov je odkazovaný vektor hodnôt v tomto type techniky zoskupovania os. V porovnaní s inými klastrami je každý objekt súčasťou klastra s minimálnym rozdielom v hodnote. Počet klastrov by mal byť preddefinovaný, a to je najväčší problém algoritmu tohto typu. Táto metodika je najbližšie k predmetu identifikácie a široko sa používa pri problémoch optimalizácie.
4. Hierarchická metóda
Metóda vytvorí hierarchický rozklad danej sady dátových objektov. Na základe toho, ako sa vytvára hierarchický rozklad, môžeme klasifikovať hierarchické metódy. Táto metóda je uvedená nasledovne
- Aglomeračný prístup
- Rozdeľovací prístup
Aglomeračný prístup je známy aj ako prístup pomocou tlačidiel. Tu začíname každým objektom, ktorý tvorí samostatnú skupinu. Pokračuje v spájaní predmetov alebo skupín blízko seba
Divisívny prístup je známy aj ako prístup zhora nadol. Začneme so všetkými objektmi v rovnakom klastri. Táto metóda je rigidná, tj nemôže byť nikdy vrátená po dokončení fúzie alebo rozdelenia
5. Metóda založená na mriežke
Metódy založené na mriežke fungujú v objektovom priestore namiesto rozdelenia údajov do mriežky. Mriežka je rozdelená na základe charakteristík údajov. Použitím tejto metódy je ľahké spravovať nečíselné údaje. Poradie údajov nemá vplyv na rozdelenie mriežky. Dôležitou výhodou modelu založeného na mriežke je rýchlejšia realizácia.
Výhody hierarchického zoskupovania sú nasledujúce
- Uplatňuje sa na akýkoľvek typ atribútu.
- Poskytuje flexibilitu súvisiacu s úrovňou granularity.
6. Metóda založená na modeli
Táto metóda používa predpokladaný model založený na rozdelení pravdepodobnosti. Zoskupením funkcie hustoty táto metóda vyhľadá zhluky. Odráža to priestorové rozloženie dátových bodov.
Aplikácia klastrov v dolovaní dát
Zhlukovanie môže pomôcť v mnohých oblastiach, napríklad v biológii, rastlinách a zvieratách klasifikovaných podľa ich vlastností, ako aj pri marketingu. Zhlukovanie pomôže pri identifikácii zákazníkov určitého záznamu zákazníka s podobným správaním. V mnohých aplikáciách, ako je prieskum trhu, rozpoznávanie vzorov, spracovanie údajov a obrázkov, sa zhluková analýza používa vo veľkom počte. Zhlukovanie môže tiež pomôcť inzerentom v ich zákazníckej základni nájsť rôzne skupiny. A ich skupiny zákazníkov môžu byť definované nákupnými vzormi. V biológii sa používa na určenie taxonómie rastlín a zvierat, na kategorizáciu génov s podobnou funkčnosťou a na nahliadnutie do štruktúr, ktoré sú súčasťou populácie. V databáze pozorovania Zeme umožňuje zoskupovanie tiež ľahšie nájsť oblasti s podobným využitím v krajine. Pomáha identifikovať skupiny domov a bytov podľa typu, hodnoty a miesta určenia domov. Zhlukovanie dokumentov na webe je tiež užitočné pri získavaní informácií. Klastrová analýza je nástroj na získanie prehľadu o distribúcii údajov na pozorovanie charakteristík každého klastra ako funkcie dolovania dát.
záver
Zhlukovanie je dôležité pri získavaní údajov a ich analýze. V tomto článku sme videli, ako možno zoskupovanie dosiahnuť pomocou rôznych algoritmov zoskupovania, ako aj ich použitie v reálnom živote.
Odporúčaný článok
Toto bol sprievodca „Čo je zoskupovanie v ťažbe údajov“. Tu sme diskutovali o konceptoch, definícii, vlastnostiach, použití klastrov v dolovaní dát. Viac informácií nájdete aj v ďalších navrhovaných článkoch -
- Čo je spracovanie údajov?
- Ako sa stať analytikom údajov?
- Čo je to SQL Injection?
- Definícia toho, čo je SQL Server?
- Prehľad architektúry dolovania dát
- Klastrovanie v strojovom učení
- Hierarchický klastrovací algoritmus
- Hierarchické zoskupovanie Aglomeračné a deliace sa zoskupovanie