

Úvod do programu Spark SQL
Ako vieme, spojenia v SQL sa používajú na kombinovanie údajov alebo riadkov z dvoch alebo viacerých tabuliek na základe spoločného poľa medzi nimi. V tejto téme sa dozvieme viac o pripojení k programu Spark SQL Pripojeniu k programu Spark SQL.
V prostredí Spark SQL sú Dataframe alebo Dataset tabuľková štruktúra v pamäti, ktorá má riadky a stĺpce, ktoré sú distribuované do viacerých uzlov. Podobne ako bežné tabuľky SQL, aj na dátovom serveri Dataframe alebo Dataset prítomnom v programe Spark SQL môžeme vykonávať operácie spojenia na základe spoločného poľa medzi nimi.
V SQL sú k dispozícii rôzne typy operácií spojenia. V závislosti od obchodného prípadu sme sa rozhodli pre operáciu Pripojiť sa. V nasledujúcej časti ukážeme jednotlivé typy spojení s príkladom.
Typy spojenia v programe Spark SQL
Nasledujú rôzne typy spojení, ktoré sú k dispozícii v programe Spark SQL:
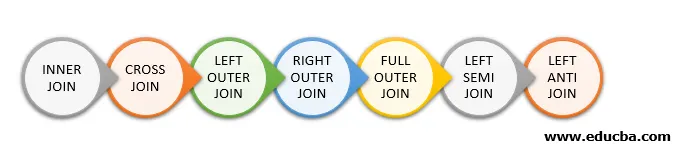
- VNÚTORNÝ PRIESTOR
- CROSS JOIN
- Vľavo mimo spojenia
- PRÁVO VONKAJŠÍM PRIPOJENÍM
- PLNÝ VONKAJŠÍ PRIESTOR
- ĽAVÝ SEMI SPOJOVAŤ
- ĽAVÝ ANTI JOIN
Príklad vytvorenia údajov
Nasledujúce údaje použijeme na demonštráciu rôznych typov spojení:
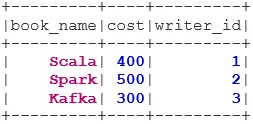
Súbor údajov knihy:
case class Book(book_name: String, cost: Int, writer_id:Int)
val bookDS = Seq(
Book("Scala", 400, 1),
Book("Spark", 500, 2),
Book("Kafka", 300, 3),
Book("Java", 350, 5)
).toDS()
bookDS.show()

Súbor údajov spisovateľa:
case class Writer(writer_name: String, writer_id:Int)
val writerDS = Seq(
Writer("Martin", 1),
Writer("Zaharia " 2),
Writer("Neha", 3),
Writer("James", 4)
).toDS()
writerDS.show()

Typy pripojení
Ďalej uvádzame 7 rôznych typov pripojení:
1. VNÚTORNÝ PRIESTOR
INNER JOIN vráti množinu údajov, ktorá má riadky, ktoré majú zodpovedajúce hodnoty v oboch množinách údajov, tj hodnota spoločného poľa bude rovnaká.
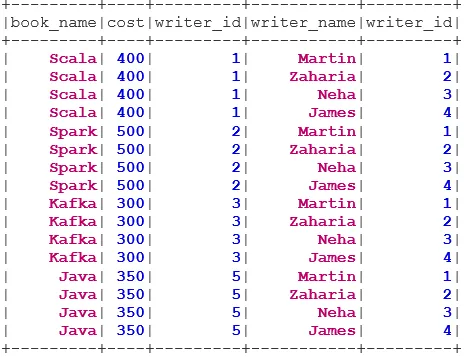
val BookWriterInner = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "inner")
BookWriterInner.show()

2. CROSS JOIN
CROSS JOIN vráti množinu údajov, čo je počet riadkov v prvom množine údajov vynásobený počtom riadkov v druhom množine údajov. Takýto výsledok sa nazýva karteziánsky výrobok.
Predpoklad: Pre použitie krížového spojenia musí byť parameter spark.sql.crossJoin.enabled nastavený na true. V opačnom prípade bude vyvolaná výnimka.
spark.conf.set("spark.sql.crossJoin.enabled", true)
val BookWriterCross = bookDS.join(writerDS)
BookWriterCross.show()
3. ĽAVÝ VONKAJŠÍ PRIESTOR
ĽAVÉ VONKAJŠIE ZARIADENIE vráti množinu údajov, ktorá obsahuje všetky riadky z ľavého množiny údajov a zodpovedajúce riadky z pravého množiny údajov.
val BookWriterLeft = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftouter")
BookWriterLeft.show()

4. PRÁVO VONKAJŠIEHO PRIPOJENIA
PRÁVO VONKAJŠEJ VONKY vráti množinu údajov, ktorá obsahuje všetky riadky zo správneho súboru údajov, a zhodné riadky z ľavého súboru údajov.
val BookWriterRight = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "rightouter")
BookWriterRight.show()

5. PLNÝ VONKAJŠÍ PRIESTOR
FULL OUTER JOIN vráti množinu údajov, ktorá má všetky riadky, keď existuje zhoda v ľavom alebo pravom súbore údajov.
val BookWriterFull = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "fullouter")
BookWriterFull.show()

6. ĽAVÁ POLOŽKA VSTUPU
ĽAVÝ SEMI JOIN vráti množinu údajov, ktorá má všetky riadky z ľavého súboru údajov, pričom ich korešpondencia je v správnom súbore údajov. Na rozdiel od LEFT OUTER JOIN, vrátený dataset v LEFT SEMI JOIN obsahuje iba stĺpce z ľavého datasetu.
val BookWriterLeftSemi = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftsemi")
BookWriterLeftSemi.show()
7. ĽAVÝ ANTI JOIN
ANTI SEMI JOIN vráti množinu údajov, ktorá obsahuje všetky riadky z ľavého súboru údajov, ktoré nemajú zodpovedajúce údaje v správnom súbore údajov. Obsahuje tiež iba stĺpce z ľavého súboru údajov.
val BookWriterLeftAnti = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftanti")
BookWriterLeftAnti.show()

Záver - Pripojte sa k programu Spark SQL
Spájanie údajov je jednou z najbežnejších a najdôležitejších operácií pri plnení našich obchodných prípadov. Spark SQL podporuje všetky základné typy spojení. Pri pripájaní musíme brať do úvahy aj výkon, pretože môžu vyžadovať veľké sieťové prenosy alebo dokonca vytvoriť súbory údajov, ktoré sú nad rámec našej schopnosti zvládnuť. Na zvýšenie výkonu používa Spark SQL optimalizátor na zmenu poradia alebo potlačenia filtrov. Iskra tiež obmedzuje nebezpečné pripojenie i. e CROSS JOIN. Pre použitie krížového spojenia musí byť spark.sql.crossJoin.enabled explicitne nastavený na true.
Odporúčané články
Toto je sprievodca, ako sa zapojiť do programu Spark SQL. Tu diskutujeme o rôznych typoch pripojení dostupných v Spark SQL s príkladom. Môžete sa tiež pozrieť na nasledujúci článok.
- Typy pripojení v SQL
- Tabuľka v SQL
- SQL Vložiť dotaz
- Transakcie v SQL
- Filtre PHP Ako overiť vstup používateľa pomocou rôznych filtrov?