
Čo je to algoritmus SVM?
SVM znamená Support Vector Machine. SVM je dohliadaný algoritmus strojového učenia, ktorý sa bežne používa na klasifikáciu a regresné výzvy. Bežnými aplikáciami algoritmu SVM sú systém detekcie narušenia, rozpoznávanie rukopisu, predpoveď štruktúry proteínov, detekcia steganografie v digitálnych obrazoch atď.
V algoritme SVM je každý bod reprezentovaný ako údajová položka v n-rozmernom priestore, kde hodnota každého prvku je hodnota konkrétnej súradnice.
Po vykreslení bola klasifikácia vykonaná nájdením roviny hype, ktorá rozlišuje dve triedy. Ak chcete porozumieť tejto koncepcii, pozrite si obrázok nižšie.
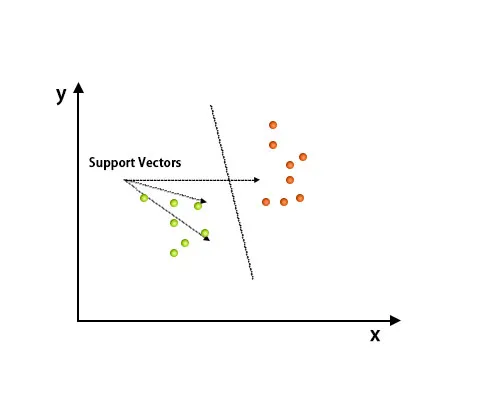
Algoritmus Support Vector Machine sa používa hlavne na riešenie problémov klasifikácie. Podporné vektory nie sú nič iné ako súradnice každej údajovej položky. Podpora Vector Machine je hranica, ktorá rozlišuje dve triedy pomocou hyper-roviny.
Ako funguje algoritmus SVM?
Vo vyššie uvedenej časti sme diskutovali o diferenciácii dvoch tried pomocou hyper-roviny. Teraz uvidíme, ako tento algoritmus SVM skutočne funguje.
Scenár 1: Identifikujte správnu hyperrovinu
Tu sme vzali tri hyper-roviny, tj A, B a C. Teraz musíme určiť správnu hyper-rovinu na klasifikáciu hviezdy a kruhu.
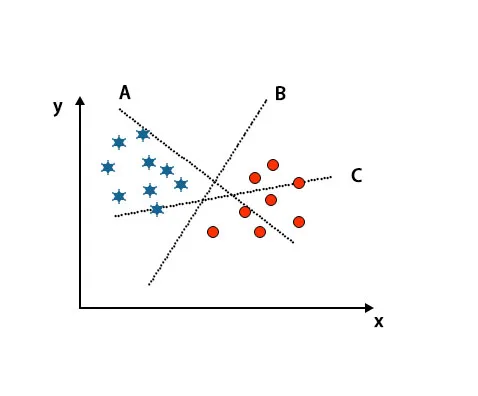
Na identifikáciu správnej hyper-roviny by sme mali poznať palec pravidlo. Vyberte hyper rovinu, ktorá rozlišuje dve triedy. Na vyššie uvedenom obrázku hyper-rovina B veľmi dobre rozlišuje dve triedy.
Scenár 2: Identifikujte pravú hyperrovinu
Tu sme vzali tri hyperplochy, tj A, B a C. Tieto tri hyperplochy už veľmi dobre rozlišujú triedy.
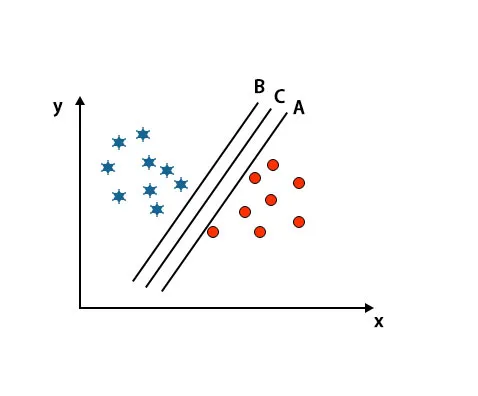
V tomto scenári, aby sme identifikovali správnu hyperrovinu, zväčšujeme vzdialenosť medzi najbližšími dátovými bodmi. Táto vzdialenosť nie je nič iné ako okraj. Pozri obrázok nižšie.
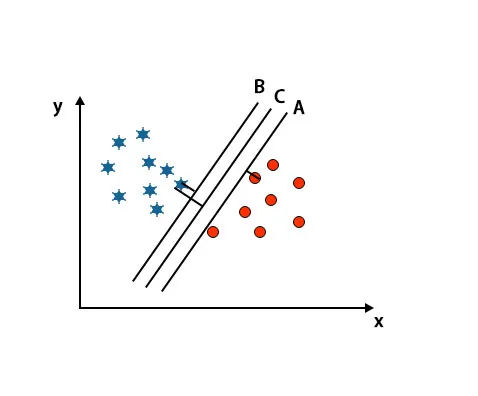
Na vyššie uvedenom obrázku je okraj hyperplochy C vyšší ako hyperplocha A a hyperplocha B. Takže v tomto scenári je C pravá hyperplocha. Ak vyberieme hyperplán s minimálnym rozpätím, môže to viesť k nesprávnej klasifikácii. Preto sme si vybrali hyperplán C s maximálnym rozpätím kvôli robustnosti.
Scenár 3: Identifikujte správnu hyperrovinu
Poznámka: Na identifikáciu hyperplochy postupujte podľa rovnakých pravidiel, aké sú uvedené v predchádzajúcich častiach.
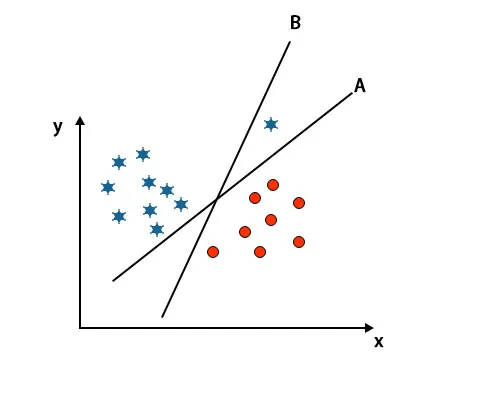
Ako vidíte na vyššie uvedenom obrázku, okraj hyperplochy B je vyšší ako okraj hyperplochy A, preto niektoré vyberú hyper rovinu B ako pravú. Ale v algoritme SVM vyberie túto hyper-rovinu, ktorá klasifikuje triedy presne pred maximalizáciou marže. V tomto scenári hyper rovina A klasifikovala všetky presne a vyskytla sa chyba pri klasifikácii hyper roviny B. Preto A je pravá hyper rovina.
Scenár 4: Klasifikácia dvoch tried
Ako vidíte na nižšie uvedenom obrázku, nedokážeme rozlíšiť dve triedy pomocou priamky, pretože jedna hviezda leží ako odľahlá hodnota v inej triede kružníc.
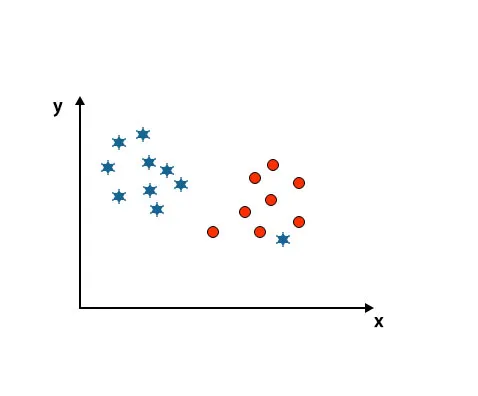
Jedna hviezda je tu v inej triede. Pre triedu hviezd je táto hviezda odľahlá. Kvôli robustnosti algoritmu SVM nájde správnu hyperpláziu s vyššou rezervou ignorujúcou odľahlú hodnotu.
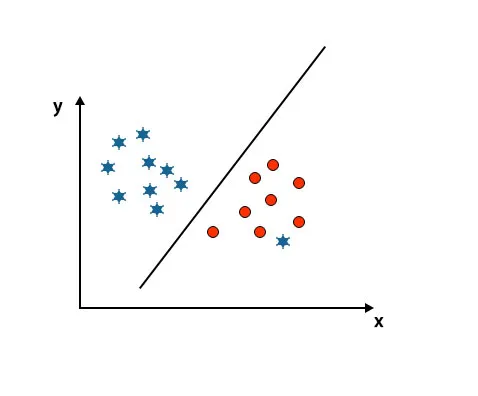
Scenár č. 5: Jemná hyper rovina na rozlíšenie tried
Doteraz sme hľadali lineárnu hyperrovinu. Na nižšie uvedenom obrázku nemáme medzi triedami lineárnu hyper rovinu.
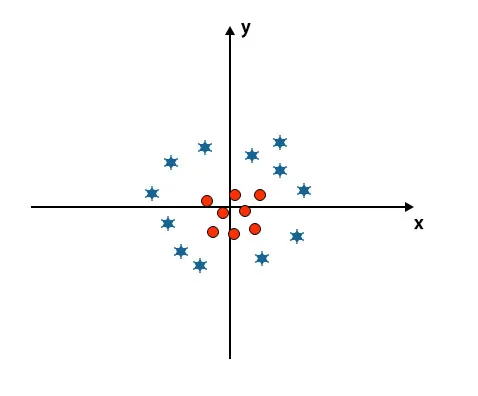
Na klasifikáciu týchto tried SVM zavádza niektoré ďalšie funkcie. V tomto scenári použijeme túto novú funkciu z = x 2 + y 2.
Nakreslí všetky údajové body na osi x a z.

Poznámka
- Všetky hodnoty na osi z by mali byť kladné, pretože z sa rovná súčtu x na druhú a na druhú na druhú.
- Na vyššie uvedenom diagrame sú červené kruhy uzavreté k začiatku osi x a osi y, čo vedie k tomu, že hodnota z je nižšia a hviezda je presne opačná kružnice, je vzdialená od začiatku osi x. a os y, vedúca k hodnote z.
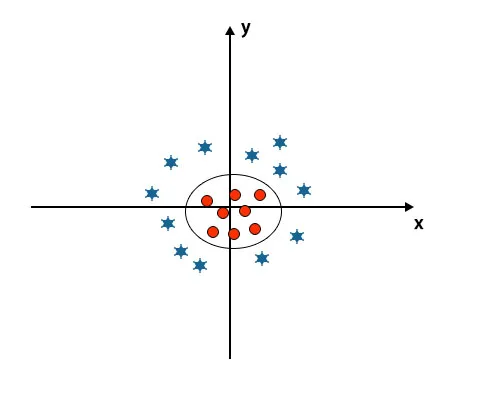
V algoritme SVM je ľahké klasifikovať pomocou lineárneho hyperplánu medzi dvoma triedami. Vyvstáva tu však otázka, mali by sme pridať túto vlastnosť SVM na identifikáciu hyper-roviny. Takže odpoveď znie nie, na vyriešenie tohto problému má SVM techniku, ktorá sa všeobecne nazýva trik jadra.
Trik s jadrom je funkcia, ktorá transformuje dáta do vhodnej formy. Existujú rôzne typy funkcií jadra, ktoré sa používajú v algoritme SVM, tj polynom, lineárny, nelineárny, funkcia radiálneho základu atď. Tu sa pomocou triku jadra prevádza nízko-rozmerný vstupný priestor na priestor vyššej dimenzie.
Keď sa pozrieme na hyperplošinu na pôvod osi a osi y, vyzerá to ako kruh. Pozri obrázok nižšie.
Výhody SVM algoritmu
- Aj keď sú vstupné údaje nelineárne a neoddeliteľné, SVM generujú presné výsledky klasifikácie kvôli svojej robustnosti.
- V rozhodovacej funkcii používa podskupinu tréningových bodov nazývaných podporné vektory, a preto je efektívne z hľadiska pamäte.
- Je užitočné vyriešiť akýkoľvek zložitý problém vhodnou funkciou jadra.
- V praxi sú modely SVM všeobecné, s menším rizikom nadmerného osadenia v SVM.
- SVM funguje skvele pre klasifikáciu textu a pri hľadaní najlepšieho lineárneho oddeľovača.
Nevýhody algoritmu SVM
- Pri práci s veľkými množinami údajov to trvá dlhý čas.
- Je ťažké pochopiť konečný model a individuálny vplyv.
záver
Bola sprevádzaná algoritmom Support Vector Machine Algorithm, čo je algoritmus strojového učenia. V tomto článku sme diskutovali o tom, čo je algoritmus SVM, ako to funguje a aké sú jeho výhody.
Odporúčané články
Toto bol sprievodca algoritmom SVM. Tu diskutujeme o jeho práci so scenárom, výhodami a nevýhodami algoritmu SVM. Ďalšie informácie nájdete aj v nasledujúcich článkoch -
- Algoritmy dolovania údajov
- Techniky dolovania dát
- Čo je to strojové učenie?
- Nástroje strojového učenia
- Príklady algoritmu C ++