

Úvod do ANOVA v R
Nasledujúci článok ANOVA v R poskytuje náčrt na porovnanie strednej hodnoty rôznych skupín. Analýza variácie (ANOVA) je veľmi bežná technika použitá na porovnanie strednej hodnoty rôznych skupín. Model ANOVA sa používa na testovanie hypotéz, keď sa pre populáciu generuje určitý predpoklad alebo parameter a na určenie, či je hypotéza pravdivá alebo nepravdivá, sa používa štatistická metóda.
Hypotéza je odvodená z predpokladu výskumníka a dostupných informácií o populácii. ANOVA sa nazýva Analýza odchýlok a používa sa na testovanie hypotéz, pri ktorých sa vyžaduje meranie prostriedkov premennej vo viacerých nezávislých skupinách.
Napríklad v laboratóriu, kde sa skúmajú alebo vymýšľajú nové lieky na obezitu, porovnajú vedci výsledok experimentálnej a štandardnej liečby. V štúdii obezity sa dajú odvodiť cenné výsledky, keď sa priemerná miera obezity populácie dá porovnať v rôznych vekových skupinách. V tomto prípade by sme chceli pozorovať priemernú mieru obezity medzi rôznymi vekovými skupinami, ako je vek (5 až 18), (19, 35) a (36 až 50). Metóda ANOVA sa uplatňuje, pretože existujú viac ako dve skupiny, ktoré sú nezávislé. ANOVA metóda sa používa na porovnanie strednej obezity nezávislých skupín. Používa sa funkcia aov () a Syntax je aov (vzorec, data = dataframe) V tomto článku sa dozvieme o modeli ANOVA a ďalej diskutujeme o jednosmernom a obojsmernom modeli ANOVA spolu s príkladmi.
Prečo ANOVA?
- Táto technika sa používa na zodpovedanie hypotézy pri analýze viacerých skupín údajov. Existuje niekoľko štatistických prístupov, avšak ANOVA v R sa uplatňuje, keď je potrebné urobiť porovnanie na viac ako dvoch nezávislých skupinách, ako v predchádzajúcom príklade troch rôznych vekových skupín.
- Technika ANOVA meria priemer nezávislých skupín, aby výskumníkom poskytla výsledok hypotézy. Na dosiahnutie presných výsledkov sa musia brať do úvahy priemery vzoriek, veľkosť vzorky a štandardná odchýlka od každej jednotlivej skupiny.
- Je možné pozorovať priemer jednotlivo pre každú z troch skupín na porovnanie. Tento prístup má však obmedzenia a môže sa ukázať ako nesprávny, pretože tieto tri porovnania nezohľadňujú celkové údaje, a preto môžu viesť k chybe typu 1. R nám poskytuje funkciu na vykonanie analýzy ANOVA na preskúmanie variability medzi nezávislými skupinami údajov. Analýzu ANOVA je päť stupňov. V prvej fáze sú údaje usporiadané vo formáte csv a pre každú premennú sa vygeneruje stĺpec. Jeden zo stĺpcov by bola závislá premenná a zostávajúce sú nezávislé. V druhej fáze sa údaje načítajú v štúdiu R a pomenujú sa správne. V tretej fáze je súbor údajov pripojený k jednotlivým premenným a načítaný z pamäte. Nakoniec je definovaná a analyzovaná ANOVA v R. V nižšie uvedených častiach som uviedol niekoľko príkladov prípadovej štúdie, v ktorých by sa mali používať techniky ANOVA.
- Na 12 poliach bolo testovaných šesť insekticídov a vedci spočítali počet chýb, ktoré zostali v každom poli. Teraz musia poľnohospodári vedieť, či majú insekticídy nejaký význam, a ak áno, ktorý z nich najlepšie používajú. Na túto otázku odpoviete pomocou funkcie aov () na vykonanie ANOVA.
- Päťdesiat pacientov bolo liečených jedným z piatich liekov na zníženie hladiny cholesterolu (trt). Tri z liečebných podmienok zahŕňali rovnaké liečivo podávané ako 20 mg jedenkrát denne (1 krát) 10 mg dvakrát denne (2 krát) 5 mg štyrikrát denne (4 krát). Dve zostávajúce podmienky (drugD a drugE) predstavovali konkurenčné lieky. Ktoré ošetrenie liekom spôsobilo najväčšiu redukciu cholesterolu (odpoveď)?
ANOVA jednosmerná
- Jednosmerná metóda je jednou zo základných metód ANOVA, pri ktorých sa používa analýza rozptylu a porovnáva sa priemerná hodnota viacerých skupín populácie.
- Jednosmerná ANOVA dostala svoje meno kvôli dostupnosti jednosmerne klasifikovaných údajov. V jednosmernej ANOVA môže byť k dispozícii jediná závislá premenná a jedna alebo viac nezávislých premenných.
- Napríklad vykonáme techniku ANOVA na súbore údajov o cholesterole. Súbor údajov obsahuje dve premenné trt (ktoré sú ošetreniami na 5 rôznych úrovniach) a premenné odpovede. Nezávislá premenná - skupiny liečby drogami, závislá premenná - znamená 2 alebo viac skupín ANOVA. Z týchto výsledkov môžete potvrdiť, že užívanie dávok 5 mg 4-krát denne bolo lepšie ako užívanie dávky 20 mg jedenkrát denne. Liečivo D má lepšie účinky v porovnaní s liečivom E
Liečivo D poskytuje lepšie výsledky, ak sa užíva v 20 mg dávkach v porovnaní s liečivom E
Používa množinu cholesterolu v balíku multcompinstall.packages('multcomp')
library(multcomp)
str(cholesterol)
attach(cholesterol)
aov_model <- aov(response ~ trt)
ANOVA F test na ošetrenie (trt) je významný (p <0, 0001), čo poskytuje dôkaz, že týchto päť ošetrení
# nie sú všetky rovnako efektívne.
Zhrnutie (aov_model)
detach (cholesterol)

Funkcia plotmeans () v balíku gplots sa môže použiť na vytvorenie grafu skupinových prostriedkov a ich intervalov spoľahlivosti. To jasne ukazuje rozdiely v liečbeinstall.packages('gplots')
library(gplots)
plotmeans(response ~ trt, xlab="Treatment", ylab="Response",
main="Mean Plot\nwith 95% CI")
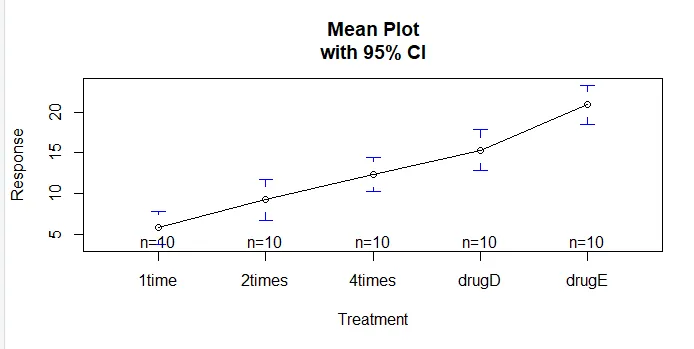
Poďme preskúmať výstup z TukeyHSD () pre párové rozdiely medzi prostriedkami skupiny
TukeyHSD (aov_model)
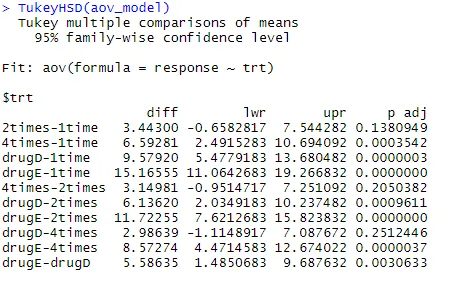
Priemerné zníženie cholesterolu 1-krát a 2-krát sa navzájom významne nelíšia (p = 0, 138), zatiaľ čo rozdiel medzi 1-krát a 4-krát je významne odlišný (p <0, 001).
par (mar = c (5, 8, 4, 2)) # zvýšenie grafu ľavého okraja (TukeyHSD (aov_model), las = 2)
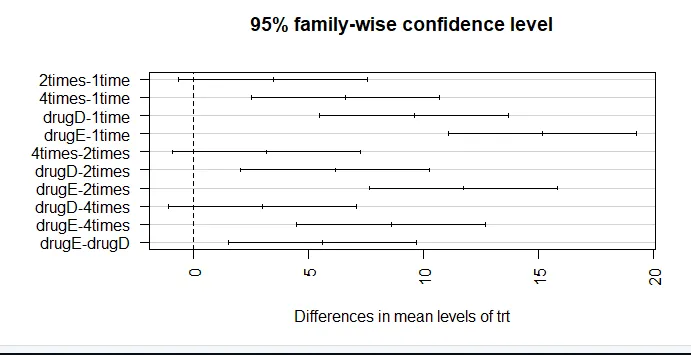
Dôvera vo výsledky závisí od stupňa, v akom vaše údaje spĺňajú predpoklady, z ktorých vychádzajú štatistické testy. V jednosmernej ANOVA sa predpokladá, že závislá premenná je normálne distribuovaná a má v každej skupine rovnaké rozptyl. Na vyhodnotenie knižnice predpokladov normality (auto) môžete použiť graf QQ.
Graf QQ (lm (odozva ~ trt, dáta = cholesterol), simulovať = TRUE, main = ”QQ Plot”, label = FALSE)
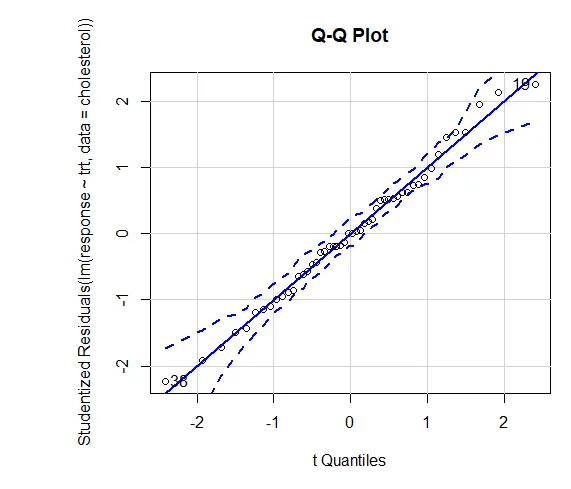
Bodkovaná čiara = 95% miera spoľahlivosti, čo naznačuje, že predpoklad normality bol splnený pomerne dobre. ANOVA predpokladá, že rozdiely sú rovnaké v rámci skupín alebo vzoriek. Bartlettov test sa môže použiť na overenie tohto predpokladu
bartlett.test (odozva ~ trt, dáta = cholesterol). Bartlettov test ukazuje, že odchýlky v piatich skupinách sa významne nelíšia (p = 0, 97).
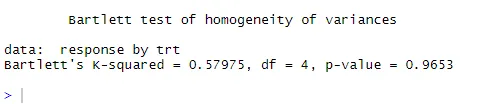
ANOVA je tiež citlivý na test na odľahlé hodnoty pre odľahlé hodnoty pomocou funkcie outlierTest () v balení automobilu. Možno nebudete musieť spustiť tento balík na aktualizáciu svojej knižnice automobilov.update.packages(checkBuilt = TRUE)
install.packages("car", dependencies = TRUE)
library(car)
outlierTest(aov_model)
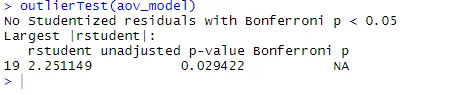
Z výstupu je vidieť, že v údajoch o cholesterole nie sú žiadne náznaky extrémnych hodnôt (NA nastane, keď je p> 1). Keď vezmeme do úvahy QQ graf, Bartlettov test a odľahlý test, údaje sa javia ako celkom vhodné pre model ANOVA.
Obojsmerná Anova
Ďalšia premenná sa pridáva do dvojcestného testu ANOVA. Ak existujú dve nezávislé premenné, budeme musieť použiť dvojsmernú ANOVA namiesto jednosmernej ANOVA techniky, ktorá sa použila v predchádzajúcom prípade, keď sme mali jednu súvislú závislú premennú a viac ako jednu nezávislú premennú. Na overenie obojsmernej ANOVA je potrebné splniť viaceré predpoklady.
- Dostupnosť nezávislých pozorovaní
- Pozorovania by sa mali bežne distribuovať
- Pri pozorovaní by mala byť odchýlka rovnaká
- Nemali by byť prítomné odľahlé hodnoty
- Nezávislé chyby
Na overenie obojsmernej ANOVA sa do súboru údajov pridá ďalšia premenná s názvom BP. Premenná udáva mieru krvného tlaku u pacientov. Chceli by sme overiť, či existuje štatistický rozdiel medzi BP a dávkou podávanou pacientom.
df <- read.csv („file.csv“)
df
anova_two_way <- aov (odpoveď ~ trt + BP, data = df)
Zhrnutie (anova_two_way)
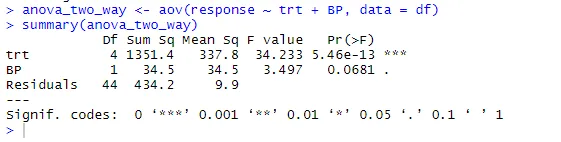
Z výstupu je možné vyvodiť záver, že trt aj BP sa štatisticky líšia od 0. Preto je možné nulovú hypotézu zamietnuť.
Výhody ANOVA v R
ANOVA test určuje rozdiel medzi dvoma alebo viacerými nezávislými skupinami. Táto technika je veľmi užitočná pri analýze viacerých položiek, ktorá je nevyhnutná pre analýzu trhu. Použitím testu ANOVA je možné získať potrebné informácie z údajov. Napríklad pri prieskume produktov, kde sa od používateľov zhromažďuje viac informácií, ako sú nákupné zoznamy, zákaznícke hodnotenia a nepáči sa. Test ANOVA nám pomáha porovnávať skupiny obyvateľstva. Skupinou môžu byť muži alebo ženy alebo rôzne vekové skupiny. Technika ANOVA pomáha pri rozlišovaní medzi strednými hodnotami rôznych skupín obyvateľstva, ktoré sú skutočne odlišné.
Záver - ANOVA v R
ANOVA je jednou z najbežnejšie používaných metód na testovanie hypotéz. V tomto článku sme vykonali test ANOVA na dátovom súbore pozostávajúcom z päťdesiatich pacientov, ktorí dostávali liečbu liekmi znižujúcimi cholesterol, a ďalej sme videli, ako je možné vykonať dvojsmernú ANOVA, keď je k dispozícii ďalšia nezávislá premenná.
Odporúčané články
Toto je sprievodca po ANOVA v R. Tu diskutujeme o jednosmernom a obojsmernom modeli Anova spolu s príkladmi a výhodami ANOVA. Môžete si tiež prečítať naše ďalšie navrhované články -
- Regresia vs. ANOVA
- Čo je to SPSS?
- Ako interpretovať výsledky pomocou testu ANOVA
- Funkcie v R