
Úvod do vrecovania a zvyšovania
Bagging a Boosting sú dve populárne metódy Ensemble. Takže predtým, ako pochopíme, Bagging a Boosting, poďme si predstaviť, čo je kompletné učenie. Je to technika na použitie viacerých algoritmov učenia na trénovanie modelov s rovnakým súborom údajov na získanie predpovede v strojovom učení. Po získaní predpovede z každého modelu použijeme techniky priemerovania modelu, ako je vážený priemer, rozptyl alebo maximálne hlasovanie, aby sme dostali konečnú predpoveď. Cieľom tejto metódy je získať lepšie predpovede ako individuálny model. To vedie k lepšej presnosti predchádzajúcej nadmernému prispôsobovaniu a znižuje predpojatosť a odchýlku. Dve populárne metódy súboru sú:
- Bagging (Bootstrap Agregating)
- posilňovanie
vrecovanie:
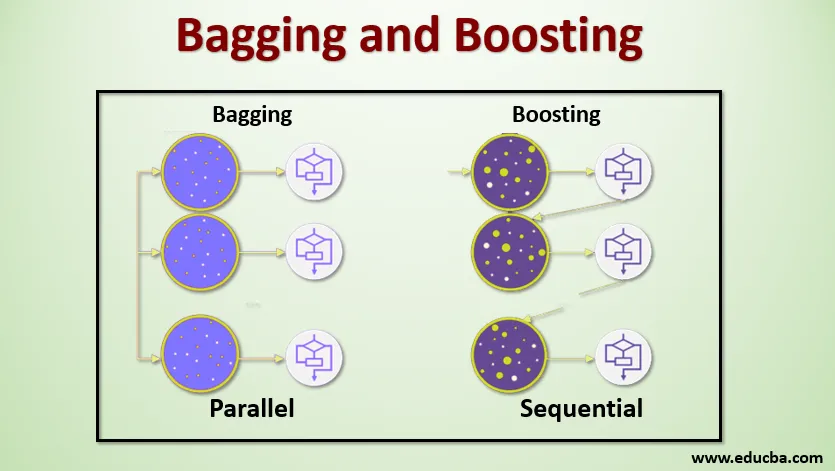
Bagging, tiež známy ako Bootstrap Aggregating, sa používa na zlepšenie presnosti a robí model všeobecnejším tým, že znižuje odchýlky, tj tým, že sa vyhýba nadmernému vybavovaniu. V tomto berieme viac podmnožín súboru údajov o školení. Pre každú podmnožinu berieme model s rovnakými algoritmami učenia, ako je rozhodovací strom, logistická regresia atď., Aby sme predpovedali výstup pre rovnakú sadu testovacích údajov. Akonáhle budeme mať predpoveď z každého modelu, potom použijeme techniku priemerovania modelu, aby sme získali konečný výstup predikcie. Jednou z najznámejších techník používaných v Baggingu je Random Forest . V náhodnom lese používame viac rozhodovacích stromov.
Podpora :
Posilnenie sa primárne používa na zníženie zaujatosti a rozptylu v technike pod dohľadom. Vzťahuje sa na rodinu algoritmov, ktorá prevádza slabých študentov (základných študentov) na silných študentov. Slabým žiakom sú klasifikátory, ktoré sú správne len do malej miery so skutočnou klasifikáciou, zatiaľ čo silní študenti sú klasifikátory, ktoré dobre korelujú so skutočnou klasifikáciou. Málo známych techník Boostingu je AdaBoost, GRADIENT BOOSTING, XgBOOST (Extreme Gradient Boosting). Takže teraz vieme, čo je vrecovanie a podpora a aké sú ich úlohy v strojovom učení.
Spracovanie vrecovania a zvyšovania
Teraz pochopme, ako funguje vrecovanie a podpora:
vrecovanie
Aby sme pochopili fungovanie Baggingu, predpokladajme, že máme počet modelov N a množinu údajov D. Kde m je počet údajov an je počet funkcií v jednotlivých údajoch. A máme robiť binárnu klasifikáciu. Najprv rozdelíme dátový súbor. Tento súbor údajov zatiaľ rozdelíme iba na školiace a testovacie sady. Nazvime súbor údajov o školení, kde je celkový počet príkladov školení.
Vezmite vzorku záznamov z tréningovej sady a použite ju na vyškolenie prvého modelu, ktorý hovorí m1. Pri nasledujúcom modeli m2 preorientuje tréningovú súpravu a odoberie ďalšiu vzorku zo výcvikovej súpravy. Urobíme to isté pre počet modelov N. Pretože preberáme súbor údajov o školení a odoberáme vzorky z neho bez toho, aby sme zo súboru údajov niečo odstránili, je možné, že máme dva alebo viac záznamov o údajoch o školení vo viacerých vzorkách. Táto technika prevzorkovania súboru údajov o školení a poskytnutia vzorky modelu sa nazýva vzorkovanie riadkov s nahradením. Predpokladajme, že sme trénovali každý model a teraz chceme vidieť predpoveď testovacích údajov. Pretože pracujeme na výstupe binárnej klasifikácie, môže byť buď 0 alebo 1. Testovacia množina údajov sa odovzdáva každému modelu a z každého modelu dostaneme predpoveď. Povedzme, že z N modelov viac ako N / 2 predpovedalo, že to bude 1, preto pomocou techniky priemerovania modelu, ako je napríklad maximálny hlas, môžeme povedať, že predpokladaný výstup pre testovacie údaje je 1.
posilňovanie
Pri posilňovaní berieme záznamy zo súboru údajov a postupne ich odovzdávame základným žiakom. Tu môžu byť základnými študentmi akýkoľvek model. Predpokladajme, že máme v súbore údajov m počet záznamov. Potom prejdeme pár záznamov, aby sme založili žiaka BL1 a trénovali ho. Akonáhle sa BL1 vyškolí, odovzdáme všetky záznamy z množiny údajov a uvidíme, ako funguje základný žiak. Pre všetky záznamy, ktoré sú základným žiakom klasifikované nesprávne, berieme ich iba a odovzdáme ich inému základnému žiakovi, ktorý hovorí BL2, a súčasne odovzdávame nesprávne záznamy klasifikované BL2, aby sme trénovali BL3. Bude to pokračovať, pokiaľ neurčíme určitý počet základných modelov študentov, ktoré potrebujeme. Nakoniec skombinujeme výstupy z týchto základných študentov a vytvoríme silného študenta, výsledkom čoho je zlepšenie predikčnej schopnosti modelu. Ok. Takže teraz vieme, ako funguje Bagging a Boosting.
Výhody a nevýhody vrecovania a zvyšovania
Nižšie sú uvedené hlavné výhody a nevýhody.
Výhody vrecovania
- Najväčšou výhodou vrecovania je, že viac slabých študentov môže pracovať lepšie ako jeden silný študent.
- Poskytuje stabilitu a zvyšuje presnosť algoritmu strojového učenia, ktorý sa používa pri štatistickej klasifikácii a regresii.
- Pomáha pri znižovaní rozptylu, tj zabraňuje nadmernému osadeniu.
Nevýhody vrecovania
- Ak nie je správne modelovaný, môže to viesť k vysokému skresleniu, čo môže viesť k nedostatočnému osadeniu.
- Pretože musíme používať viac modelov, je to výpočtovo nákladné a nemusí byť vhodné v rôznych prípadoch použitia.
Výhody zvýšenia
- Je to jedna z najúspešnejších techník pri riešení problémov dvojtriednej klasifikácie.
- Je dobré zvládnuť chýbajúce údaje.
Nevýhody zvýšenia
- Zvýšenie zložitosti algoritmu je ťažké implementovať v reálnom čase.
- Vysoká flexibilita týchto techník vedie k množstvu parametrov, ktoré majú priamy vplyv na správanie modelu.
záver
Hlavným dôvodom je to, že Bagging a Boosting sú paradigmou strojového učenia, v ktorej používame viacero modelov na vyriešenie toho istého problému a dosiahnutie lepšieho výkonu. Ak správne skombinujeme slabých študentov, môžeme získať stabilný, presný a robustný model. V tomto článku som uviedol základný prehľad o vrecovaní a posilňovaní. V nasledujúcich článkoch sa zoznámite s rôznymi technikami používanými v oboch. Na záver mi dovoľte pripomenúť, že Bagging a Boosting patria medzi najpoužívanejšie techniky kompletného učenia. Skutočné umenie zlepšovania výkonnosti spočíva vo vašom porozumení toho, kedy použiť ktorý model a ako vyladiť hyperparametre.
Odporúčané články
Toto je príručka pre Bagging a Boosting. Tu diskutujeme Úvod do vrecovania a zvyšovania a pracuje to spolu s výhodami a nevýhodami. Viac informácií nájdete aj v ďalších navrhovaných článkoch -
- Úvod do techniky súborov
- Kategórie algoritmov strojového učenia
- Algoritmus prechodu s prechodom pomocou vzorového kódu
- Čo je zosilňovací algoritmus?
- Ako vytvoriť rozhodovací strom?