

Splunk Interview Otázky a odpovede - úvod
Takže ste konečne našli svoju vysnívanú prácu v Splunk, ale premýšľate, ako rozlúštiť Splunk Interview a aké by mohli byť pravdepodobné Splunk Interview otázky pre rok 2018. Každý rozhovor je iný a rozsah práce je tiež iný. S ohľadom na to sme pre rok 2018 navrhli najbežnejšie otázky a odpovede na otázky v rámci rozhovoru za účelom dosiahnutia úspechu v pohovore.Nižšie sú uvedené najužitočnejšie otázky a odpovede týkajúce sa rozhovoru s oddelenými rozhovormi. Tieto najčastejšie otázky sú rozdelené na dve časti:
1. časť - Rozdelené otázky týkajúce sa rozhovoru (základné)
Táto prvá časť sa venuje základným otázkam a odpovediam na otázky Rozdeleného rozhovoru.
1. Čo je to Splunk? Prečo sa Splunk používa na analýzu strojových údajov?
odpoveď:
Jedným z najpoužívanejších analytických nástrojov je program Microsoft Excel a jeho nevýhodou je, že program Excel dokáže načítať iba 1048576 riadkov a strojové dáta sú vo všeobecnosti obrovské. Splunk sa hodí pri manipulácii so strojovo generovanými údajmi (veľké dáta), údaje zo serverov, zariadení alebo sietí sa dajú ľahko načítať do Splunk a dajú sa analyzovať, aby sa skontrolovala prítomnosť všetkých hrozieb, dodržiavanie predpisov, bezpečnosť atď. na monitorovanie aplikácií.
2.Vysvetlite, ako funguje Splunk
odpoveď:
Toto sú časté otázky týkajúce sa rozhovoru s oddelenými rozhovormi, ktoré boli položené počas rozhovoru. Dáta sú načítané do Splunk pomocou forwarderu, ktorý funguje ako rozhranie medzi Splunk prostredím a vonkajším svetom, potom sú tieto dáta posielané do indexátora, kde sú dáta uložené buď lokálne alebo v cloude. Indexátor indexuje údaje stroja a ukladá ich na server. Search Head je GUI, ktoré poskytuje Splunk na vyhľadávanie a analýzu údajov (prehľadáva, vizualizuje, analyzuje a vykonáva rôzne ďalšie funkcie).
Server nasadenia spravuje všetky komponenty Splunk, ako je indexovač, forwarder a vyhľadávacia hlava v prostredí Splunk. 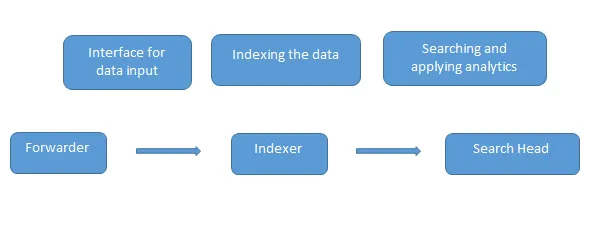
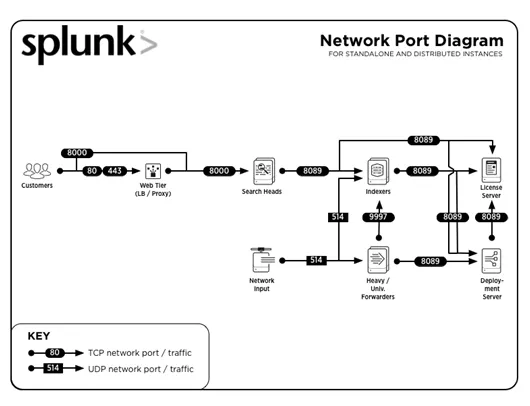
3. Aké bežné čísla portov používa Splunk?
Odpoveď :
Bežné čísla portov, na ktorých sú služby spúšťané (predvolene), sú:
| služba | Číslo portu |
| Správa / REST API | 8089 |
| Vyhľadajte hlavu / indexátor | 8000 |
| Vyhľadať hlavu | 8065, 8191 |
| Partnerský uzol klastra indexátora / člen hlavičky klastra vyhľadávania | 9887 |
| Indexer | 9997 |
| Indexovacie / súprava | 514 |
Prejdime k ďalším otázkam na pohovor s Splunk.
4. Prečo používať iba Splunk?
odpoveď:
Existuje veľa alternatív pre Splunk, ktoré dávajú veľkú konkurenciu, niektoré z nich sú uvedené nižšie:
• ELK / Logstash (otvorený zdroj)
Elasticsearch sa používa na vyhľadávanie ako v hlave Splunk, protokol Stash je určený na zhromažďovanie údajov, ktoré je podobné preposielateľovi používanému v Splunk, a Kibana sa používa na vizualizáciu údajov (hlava vyhľadávania v Splunk to isté robí)
• Graylog (open source s komerčnou verziou)
Graylog je ďalší nástroj, ktorý bol pomenovaný minulý rok vydaním 1.0. Podobne ako ELK stack má Graylog aj rôzne komponenty, ktoré používa ako svoju základnú zložku Elasticsearch, ale údaje sú uložené v Mongo DB a používajú Apache Kafka. Má dve verzie, jednu základnú verziu, ktorá je k dispozícii zadarmo, a verziu pre podniky, ktorá prichádza s funkciami ako archivácia.
• Sumo Logic (cloudová služba)
To, čo robí Splunk najlepšie zo všetkých, je to, že Splunk prichádza ako jediný balík zberača údajov, úložiska a vstavaného analytického nástroja. Splunk je tiež škálovateľný a poskytuje podporu / odbornú pomoc pre svoje podnikové vydanie.
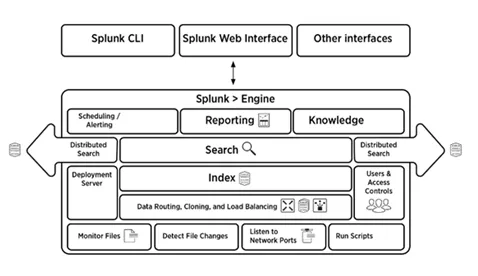
5. Stručne, vysvetlite Splunk Architecture
odpoveď:
Nižšie uvedený obrázok poskytuje stručný prehľad architektúry Splunk a jej komponentov.
2. časť - Rozdelené otázky na pohovor (rozšírené)
Pozrime sa teraz na pokročilé otázky týkajúce sa rozhovoru s Splunk.
6. Aké sú súčasti architektúry Splunk?
odpoveď:
V architektúre Splunk sú štyri komponenty. Oni sú:
- Indexer: Indexuje strojové dáta
- Forwarder: Preposiela záznamy do indexu
- Hlava vyhľadávania: Poskytuje GUI na vyhľadávanie
- Server nasadenia: Spravuje komponenty Splunk (indexer, forwarder a search head) v distribuovanom prostredí
7. Uveďte niekoľko prípadov použitia znalostných objektov.
Odpoveď :
Toto sú najčastejšie kladené otázky na pohovore v rozhovore pre Splunk. Znalostné objekty sa dajú použiť v mnohých doménach. Niekoľko príkladov je:
Monitorovanie aplikácií: Toto je možné použiť na monitorovanie aplikácií v reálnom čase pomocou nakonfigurovaných upozornení, ktoré upozornia správcov / používateľov v prípade zlyhania aplikácie.
Fyzická bezpečnosť: V prípade povodne / sopky atď. Sa údaje môžu použiť na vytvorenie prehľadu, ak vaša organizácia s takýmito údajmi zaobchádza.
Zabezpečenie siete: Zabezpečené prostredie môžete vytvoriť tak, že IP adresu neznámych zariadení zablokujete, čím znížite úniky údajov v akejkoľvek organizácii.
Manažment zamestnancov: Opotrebenie zamestnancov je jednou z výziev, ktorým čelí akákoľvek organizácia a počas výpovednej doby je možné sledovať činnosť zamestnanca, aby sa ochránili údaje organizácie, čím sa monitoruje ich činnosť a obmedzuje sa akýkoľvek iný zamestnanec v výpovednej lehote, aby nerobil to isté.,
8.Vysvetlite vyhľadávací faktor (SF) a replikačný faktor (RF)
odpoveď:
Toto sú terminológie, ktoré sa používajú v technikách klastrovania Splunk. Klaster indexov je špeciálne nakonfigurovaná skupina indexátorov Splunk Enterprise, ktorá replikuje externé údaje a používa sa na obnovu po katastrofe.
Pokiaľ ide o vyhľadávanie dokumentácie Splunk, faktor možno opísať ako „Počet vyhľadateľných kópií údajov, ktoré udržuje klaster indexátora. Predvolená hodnota faktora vyhľadávania je 2 “, zatiaľ čo faktor replikácie je definovaný ako počet kópií údajov, ktoré klaster udržuje.
Klaster indexovania má vyhľadávací faktor aj replikačný faktor, zatiaľ čo klaster vyhľadávacej hlavy má iba vyhľadávací faktor
Prejdime k ďalším otázkam na pohovor s Splunk.
9. Čo sú to Splunk vedierka? Vysvetlite životný cyklus vedra.
odpoveď:
Adresáre, v ktorých sú uložené indexované údaje, sa nazývajú Splunk vedierka a tieto obsahujú udalosti určitého obdobia. Životný cyklus vedra Splunk zahŕňa štyri stupne - horúce, teplé, chladné, mrazené a rozmrazené.
- Horúca - Táto skupina obsahuje nedávno indexované údaje a je otvorená na písanie.
- Teplý - Keď údaje spadnú do horúcich vedier, v závislosti od vašich údajov sa presunú do teplých vedier
- Studená - Ďalšou fázou po zahriatí je studená fáza, v ktorej nie je možné údaje upravovať.
- Frozen - V predvolenom nastavení indexátor vymaže údaje zo zmrazených vedier, ale tie sa dajú tiež archivovať.
- Rozmrazené - získavanie informácií z archivovaných súborov (mrazené vedro) sa nazýva rozmrazovanie.
10. Prečo by sme mali používať funkciu Splunk Alert? Aké sú rôzne možnosti pri nastavovaní upozornení?
odpoveď:
Stav pozornosti na akúkoľvek možnú chybu je známy ako upozornenie a v prostredí Splunk môžu nastať varovania prostredia v dôsledku zlyhania pripojenia alebo porušenia zabezpečenia alebo porušenia pravidiel vytvorených používateľom.
Napríklad posielanie upozornení alebo hlásenie používateľov, ktorí sa nepodarilo prihlásiť po využití ich troch pokusov v portáli, správcovi aplikácie.
Pri nastavovaní upozornení sú k dispozícii rôzne možnosti:
- Na napísanie upozornení na hipchat alebo GitHub môžete vytvoriť webhook.
- Pridajte výsledky, .csv alebo pdf alebo v súlade s textom správy, aby ste mohli identifikovať hlavnú príčinu výstrahy.
- Môžu sa vytvárať lístky a varovania sa dajú šetriť zo zariadenia alebo IP.
Odporúčaný článok
Toto bol sprievodca zoznamom otázok a odpovedí na pohovory v rozhovore, aby uchádzač mohol tieto tvrdé otázky a odpovede na pohovor ľahko zareagovať. Viac informácií nájdete aj v nasledujúcich článkoch -
- Otázky týkajúce sa rozhovorov o systéme SAS - 10 najdôležitejších otázok
- 10 vynikajúcich otázok na pohovor, ktoré musíte poznať
- 15 najúspešnejších otázok a odpovedí na rozhovor spoločnosti Oracle
- Otázky na rozhovor týkajúce sa zabezpečenia siete - najčastejšie a najčastejšie otázky
- Splunk vs Nagios