

Rozdiel medzi veľkými dátami a Apache Hadoop
Všetko je na internete. Internet obsahuje veľa údajov. Preto je všetko Big Data. Viete, že 2, 5 milióna bajtov údajov sa vytvára každý deň a hromadí sa ako veľké údaje? Naše každodenné činnosti ako komentovanie, hodnotenie páči sa mi, príspevky atď. Na sociálnych médiách, ako sú Facebook, LinkedIn, Twitter a Instagram, sa sčítavajú ako veľké údaje. Predpokladá sa, že do roku 2020 sa vytvorí takmer 1, 7 megabajtov údajov každú sekundu pre každú osobu na Zemi. Môžete si predstaviť a zvážiť, koľko údajov sa generuje za predpokladu, že každá jednotlivá osoba na Zemi. Dnes sme spojení a zdieľame naše životy online. Väčšina z nás je pripojená online. Žijeme v inteligentnom dome a používame inteligentné vozidlá a všetky sú pripojené k našim inteligentným telefónom. Viete si niekedy predstaviť, ako sa tieto zariadenia stávajú inteligentnými? Chcel by som vám dať veľmi jednoduchú odpoveď, pretože je to kvôli analýze veľkého množstva údajov, tj veľkých dát. Do piatich rokov bude na svete viac ako 50 miliárd inteligentných pripojených zariadení, všetko vyvinuté na zhromažďovanie, analýzu a zdieľanie údajov, aby sa náš život pohodlnejšie.
Toto sú predstavenia veľkých dát vs Apache Hadoop
Predstavujeme termín Big Data
Čo sú to veľké dáta? Aká veľkosť údajov sa považuje za veľkú a bude sa označovať ako veľké údaje? Máme veľa relatívnych predpokladov pre výraz Big Data. Je možné, že množstvo údajov hovorí, že 50 terabajtov sa môže považovať za veľké údaje pre začínajúce podniky, ale nemusí to byť veľké údaje pre spoločnosti ako Google a Facebook. Je to preto, že majú infraštruktúru na ukladanie a spracovanie tohto množstva údajov. Chcel by som definovať pojem Big Data ako:
- Big Data je množstvo dát, ktoré presahuje možnosti technológie na efektívne ukladanie, správu a spracovanie.
- Big Data sú dáta, ktorých rozsah, rozmanitosť a zložitosť si vyžadujú novú architektúru, techniky, algoritmy a analytiku na ich správu a extrahovanie hodnoty a skrytých znalostí z nej.
- Veľké dáta sú veľkoobjemové a vysokorýchlostné a rozmanité informačné aktíva, ktoré si vyžadujú nákladovo efektívne, inovatívne formy spracovania informácií, ktoré umožňujú vylepšený prehľad, rozhodovanie a automatizáciu procesov.
- Big Data sa týka technológií a iniciatív, ktoré zahŕňajú údaje, ktoré sú príliš rozmanité, rýchlo sa meniace alebo masívne na to, aby sa konvenčné technológie, zručnosti a infraštruktúra mohli účinne riešiť. Inak povedané, objem, rýchlosť alebo rozmanitosť údajov je príliš veľká.
3 V z veľkých dát
- Objem: Objem sa vzťahuje na množstvo / množstvo, v ktorom sa údaje vytvárajú ako každú hodinu, transakcie zákazníkov Wal-Martu poskytujú spoločnosti približne 2, 5 petabajtov údajov.
- Rýchlosť: Rýchlosť predstavuje rýchlosť, ktorou sa údaje pohybujú, ako používatelia Facebooku odosielajú v priemere 31, 25 milióna správ a prezerajú 2, 77 milióna videí každú minútu každý deň cez internet.
- Odroda: Odroda sa vzťahuje na rôzne formáty údajov, ktoré sa vytvárajú ako štruktúrované, pološtrukturované a neštruktúrované údaje. Rovnako ako odosielanie e-mailov s prílohou v službe Gmail, sú neštruktúrované údaje, zatiaľ čo uverejňovanie akýchkoľvek komentárov s niektorými externými odkazmi sa nazýva aj neštruktúrované údaje. Zdieľanie obrázkov, zvukových klipov a videoklipov je neštruktúrovaná forma údajov.
Skladovanie a spracovanie tohto obrovského objemu, rýchlosti a množstva údajov je veľkým problémom. Potrebujeme myslieť na inú technológiu ako RDBMS pre veľké dáta. Dôvodom je, že RDBMS je schopný ukladať a spracovávať iba štruktúrované údaje. Takže tu je Apache Hadoop záchranou.
Predstavujeme pojem Apache Hadoop
Apache Hadoop je softvér s otvoreným zdrojovým kódom na ukladanie údajov a spúšťanie aplikácií na klastroch komoditného hardvéru. Apache Hadoop je softvérový rámec, ktorý umožňuje distribuovať spracovanie veľkých súborov údajov cez klastre počítačov pomocou jednoduchých programovacích modelov. Je navrhnutý tak, aby sa rozšíril z jedného servera na tisíce počítačov, pričom každý z nich ponúka miestne výpočty a ukladanie. Apache Hadoop je rámec pre ukladanie a spracovanie veľkých dát. Apache Hadoop je schopný ukladať a spracovávať všetky formáty dát, ako sú štruktúrované, semi-štruktúrované a neštruktúrované údaje. Apache Hadoop je open source a komoditný hardvér priniesol revolúciu v IT priemysle. Je ľahko dostupný pre všetky úrovne spoločností. Nemusia viac investovať do založenia klastra Hadoop a na inú infraštruktúru. Pozrime sa teda na užitočný rozdiel medzi Big Data a Apache Hadoop v tomto príspevku.
Rámec Apache Hadoop
Rámec Apache Hadoop je rozdelený na dve časti:
- Distribuovaný systém súborov Hadoop (HDFS): Táto vrstva je zodpovedná za ukladanie údajov.
- MapReduce: Táto vrstva je zodpovedná za spracovanie údajov v Hadoop Cluster.
Hadoop Framework je rozdelený na architektúru master a slave. Vrstva názvu Hadoop Distributed File System (HDFS) je hlavný komponent, zatiaľ čo dátový uzol je slave komponent, zatiaľ čo vo vrstve MapReduce je Job Tracker master komponent, zatiaľ čo tracker slave komponent. Nižšie je schéma pre Apache Hadoop framework.
Prečo je Apache Hadoop dôležitý?
- Schopnosť rýchlo ukladať a spracovávať obrovské množstvo všetkých druhov údajov
- Výpočtová sila: Distribuovaný výpočtový model spoločnosti Hadoop rýchlo spracuje veľké dáta. Čím viac výpočtových uzlov používate, tým viac výpočtového výkonu máte.
- Odolnosť proti chybám: Spracovanie údajov a aplikácií je chránené pred zlyhaním hardvéru. Ak uzol klesne, úlohy sa automaticky presmerujú na iné uzly, aby sa zabezpečilo, že distribuované výpočty nezlyhajú. Automaticky sa ukladá viac kópií všetkých údajov.
- Flexibilita: Môžete uložiť ľubovoľný počet údajov a rozhodnúť sa, ako ich neskôr použijete. To zahŕňa neštruktúrované údaje, ako sú text, obrázky a videá.
- Nízke náklady: Open-source framework je bezplatný a používa komoditný hardvér na ukladanie veľkého množstva údajov.
- Škálovateľnosť: Systém môžete ľahko rozšíriť tak, aby zvládal viac údajov jednoduchým pridaním uzlov. Vyžaduje sa malá administratíva
Porovnanie medzi hlavami medzi veľkými dátami a Apache Hadoop (infografika)
Nižšie je prvé 4 porovnanie medzi veľkými dátami a Apache Hadoop
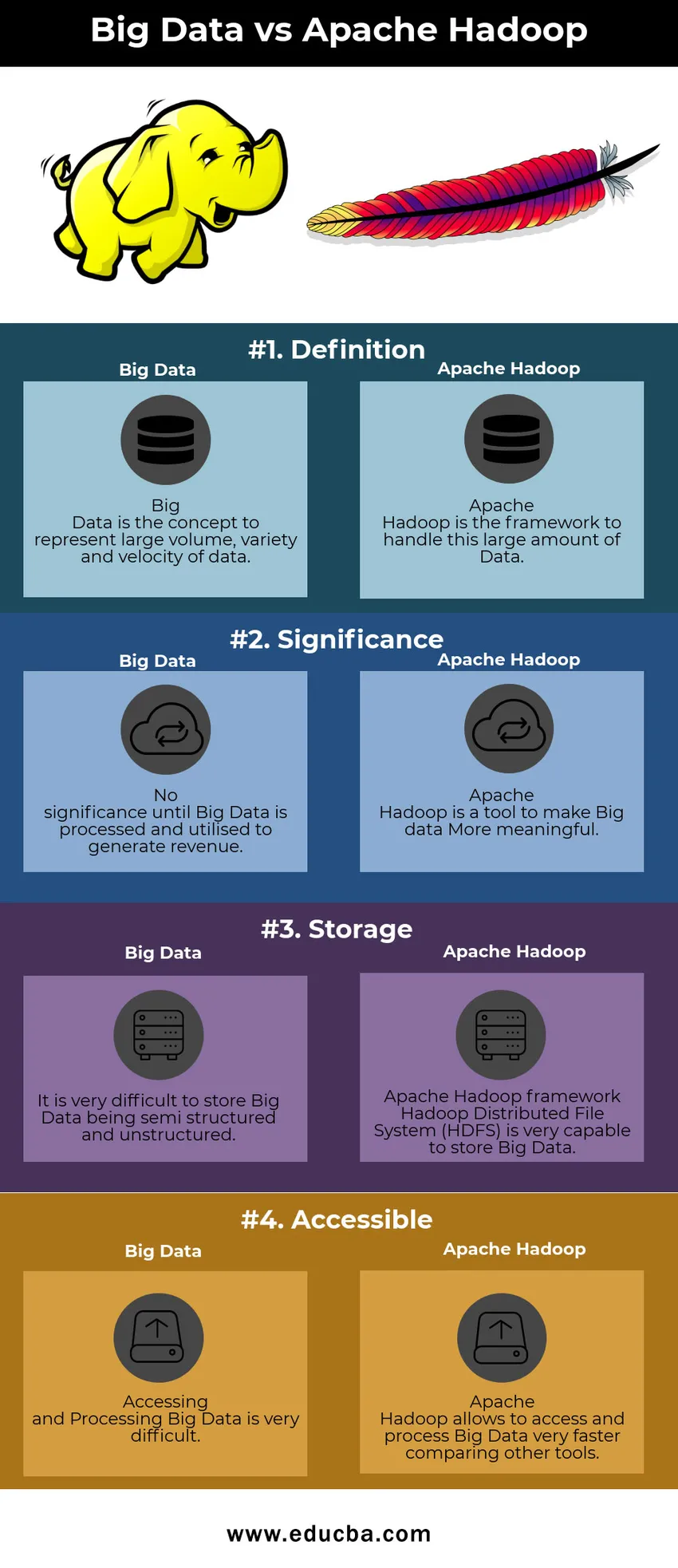
Porovnávacia tabuľka Big Data vs Apache Hadoop
Diskutujem o hlavných artefaktoch a rozlišujem medzi Big Data verzus Apache Hadoop
| Veľké dáta | Apache Hadoop | |
| definícia | Big Data je koncept, ktorý predstavuje veľký objem, rozmanitosť a rýchlosť údajov | Apache Hadoop je rámec na spracovanie tohto veľkého množstva dát |
| význam | Žiadny význam, kým sa veľké údaje nespracujú a nevyužijú na generovanie výnosov | Apache Hadoop je nástroj na vytváranie zmysluplnejších veľkých dát |
| skladovanie | Je veľmi ťažké uchovávať Big Data polostrukturované a neštruktúrované | Rámec Apache Hadoop Hadoop Distribuovaný súborový systém (HDFS) je veľmi schopný ukladať veľké dáta |
| Prístupný | Prístup a spracovanie veľkých údajov je veľmi ťažké | Apache Hadoop umožňuje veľmi rýchly prístup a spracovanie veľkých dát v porovnaní s inými nástrojmi |
Záver - Big Data vs Apache Hadoop
Nemôžete porovnávať Big Data a Apache Hadoop. Je to preto, že veľké dáta sú problémom, zatiaľ čo Apache Hadoop je riešením. Pretože množstvo údajov exponenciálne rastie vo všetkých sektoroch, je veľmi ťažké ukladať a spracovávať údaje z jedného systému. Aby sme mohli spracovať toto veľké množstvo údajov, potrebujeme distribuované spracovanie a ukladanie údajov. Apache Hadoop preto prichádza s riešením ukladania a spracovania veľkého množstva dát. Nakoniec by som dospela k záveru, že veľké dáta sú veľké množstvo komplexných údajov, zatiaľ čo Apache Hadoop je mechanizmus na ukladanie a spracovanie veľkých dát veľmi efektívne a hladko.
Odporúčaný článok
Toto bol sprievodca pre veľké dáta verzus Apache Hadoop, ich význam, porovnanie medzi dvoma hlavami, kľúčové rozdiely, porovnávacie tabuľky a závery. tento článok pozostáva zo všetkých užitočných rozdielov medzi spoločnosťami Big Data a Apache Hadoop. Ďalšie informácie nájdete aj v nasledujúcich článkoch -
- Big Data vs Data Science - Ako sa líšia?
- Top 5 veľkých dátových trendov, ktoré spoločnosti budú musieť zvládnuť
- Hadoop vs Apache Spark - zaujímavé veci, ktoré potrebujete vedieť
- Apache Hadoop vs Apache Spark | Top 10 porovnaní, ktoré musíte vedieť!