

Úvod do Python Pandas DataFrame
Viacero rozšírení pre knižnicu Python, Pandas, je možné nájsť online. Jedným takým sú dáta panela (pan) (das). Toto slovo * Panel * jemne naznačuje dvojrozmernú dátovú štruktúru prítomnú v tejto knižnici a nesmierne posilňuje jej používateľov. Táto štruktúra sa nazýva DataFrame.
Je to v podstate matica riadkov a stĺpcov, ktorá obsahuje celý váš súbor údajov, s veľmi prepracovanými možnosťami indexovania. DataFrame (DF), si možno predstaviť obrázkovo veľmi podobne ako excelovský list. Ale vďaka čomu je výkonný, je ľahkosť, s akou je možné vykonávať analytické a transformačné operácie na údajoch uložených v DataFrame.
Čo presne je dátový rámec Python Pandas?
Stránka Pydata môže byť označená ako oficiálna definícia.
Ak sa rozumie správne, spomína DataFrame ako stĺpcovú štruktúru, schopnú uložiť ľubovoľný python objekt (vrátane samotného DataFrame) ako jednu bunkovú hodnotu. (Bunka je indexovaná pomocou jedinečnej kombinácie riadkov a stĺpcov)
Dátové rámce sa skladajú z troch základných komponentov: údajov, riadkov a stĺpcov.
- Dáta: Vzťahuje sa na skutočné objekty / entity uložené v bunke v DataFrame a hodnoty reprezentované týmito entitami. Objekt má akýkoľvek platný dátový typ python, zabudovaný alebo definovaný používateľom.
- Riadky: Odkazy používané na identifikáciu (alebo indexovanie) konkrétneho súboru pozorovaní z úplných údajov uložených v dátovom rámčeku sa nazývajú riadky. Len na objasnenie predstavuje použité indexy a nielen údaje v konkrétnom pozorovaní.
- Stĺpce: Odkazy použité na identifikáciu (alebo indexovanie) nastavených atribútov pre všetky pozorovania v DataFrame. Podobne ako v prípade riadkov sa tieto údaje týkajú indexu stĺpcov (alebo hlavičiek stĺpcov) namiesto údajov v stĺpci.
Takže bez ďalších okolkov, vyskúšajme niekoľko spôsobov, ako vytvoriť tieto úžasne silné štruktúry.
Kroky na vytvorenie dátových rámčekov Python Pandas
Dátový rámec Python Pandas je možné vytvoriť pomocou nasledujúcej implementácie kódu,
1. Importujte pandy
Na vytvorenie DataFrames je potrebné importovať knižnicu pandov (tu nie je žiadne prekvapenie). My pohodlne importujeme s alias pd na referenčné objekty pod modulom.
kód:
import pandas as pd
2. Vytvorenie prvého objektu DataFrame
Po importovaní knižnice sú všetky metódy, funkcie a konštruktory k dispozícii vo vašom pracovnom priestore. Skúsme teda vytvoriť vanilkový DataFrame.
kód:
import pandas as pd
df = pd.DataFrame()
print(df)
Výkon:
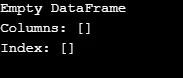
Ako je znázornené na výstupe, konštruktor vráti prázdny DataFrame.
Zamerajme sa teraz na vytváranie dátových rámcov z údajov uložených v niektorých pravdepodobných znázorneniach.
- DataFrame zo slovníka: Povedzme, že máme slovník, v ktorom je uložený zoznam spoločností v softvérovej doméne a počet rokov, v ktorých boli aktívne.
kód:
import pandas as pd
df = pd.DataFrame(
('Company':('Google', 'Amazon', 'Infosys', 'Directi'),
'Age':('21', '23', '38', '22') ))
print (df)
Pozrime sa na reprezentáciu vráteného objektu DataFrame jeho vytlačením na konzole.
Výkon:

Ako vidno, s každým kľúčom slovníka sa v DataFrame zaobchádza ako so stĺpcom a indexy riadkov sa generujú automaticky počnúc nulou.
Povedzme, že ste mu chceli dať vlastný index namiesto 0, 1, … 4. Stačí len odovzdať požadovaný zoznam ako parameter konštruktorovi a pandy urobia potrebné.
kód:
df = pd.DataFrame(
('Company':('Google', 'Amazon', 'Yahoo', 'Infosys', 'Directi'),
'Age':('21', '23', '24', '38', '22') ),
index=('Alpha', 'Beta', 'Gamma', 'Delta'))
print(df)
Výkon:
Vek spoločnosti
Alpha Google 21
Beta Amazon 23
Gamma Infosys 38
Delta Directi 22
Teraz môžete nastaviť indexy riadkov na ľubovoľnú požadovanú hodnotu.
- DataFrame zo súboru CSV: Vytvorme súbor CSV obsahujúci rovnaké údaje ako v prípade nášho slovníka. Zavolajme súbor CompanyAge.csv
Google 21
Amazon, 23
Infosys, 38
Direktíva, 22
Súbor je možné načítať do údajového rámca (za predpokladu, že je v aktuálnom pracovnom adresári) nasledovne.
kód:
csv_df = pd.read_csv(
'CompanyAge.csv', names=('Company', 'Age'), header=None)
print(csv_df)
Výkon:
Vek spoločnosti
0 Google 21
1 Amazon 23
2 Infosys 38
3 Direct 22
Nastavenie názvov parametrov , obídenie zoznamu hodnôt, ich priradí ako hlavičky stĺpcov v rovnakom poradí, v akom sú v zozname. Podobne je možné nastaviť indexy riadkov odovzdaním zoznamu parametru indexu, ako je uvedené v predchádzajúcej časti. Hlavička = žiadna označuje chýbajúce hlavičky stĺpcov v dátovom súbore.
Povedzme, že názvy stĺpcov boli súčasťou dátového súboru. Potom nastavením header = False vykoná požadovanú úlohu.
3. CompanyAgeWithHeader.csv
Spoločnosť, vek
Google 21
Amazon, 23
Infosys, 38
Direktíva, 22
Kód sa zmení na
csv_df = pd.read_csv(
'CompanyAgeWithHeader.csv', header=False)
print(csv_df)
Výkon:
Vek spoločnosti
0 Google 21
1 Amazon 23
2 Infosys 38
3 Direct 22
- DataFrame zo súboru Excel: Údaje sa často zdieľajú v excelovských súboroch, pretože zostávajú najobľúbenejším nástrojom, ktorý používajú bežní ľudia na sledovanie služby Adhoc. Preto by sa pri našej diskusii nemalo ignorovať.
Predpokladajme, že údaje, ako v spoločnosti CompanyAgeWithHeader.csv, sú teraz uložené v spoločnosti CompanyAgeWithHeader.xlsx, v hárku s názvom Spoločnosť Vek. Rovnaký dátový rámec ako vyššie bude vytvorený pomocou nasledujúceho kódu.
kód:
excel_df= pd.read_excel('CompanyAgeWithHeader.xlsx', sheet_name='CompanyAge')
print(excel_df)
Výkon:
Vek spoločnosti
0 Google 21
1 Amazon 23
2 Infosys 38
3 Direct 22
Ako vidíte, ten istý dátový rámec sa dá vytvoriť odovzdaním názvu súboru a názvu listu.
Ďalšie čítanie a ďalšie kroky
Zobrazené metódy predstavujú veľmi malú podmnožinu v porovnaní so všetkými rôznymi spôsobmi, ako je možné vytvoriť dátové rámce. Boli vytvorené s úmyslom začať jeden. Určite by ste mali preskúmať uvedené referencie a pokúsiť sa preskúmať ďalšie spôsoby, vrátane pripojenia k databáze, aby ste mohli čítať údaje priamo do DataFrame.
záver
Pandas DataFrame sa ukázal byť meničom hier vo svete Data Science a Data Analytics a je vhodný aj pre krátkodobé ad-hoc projekty. Dodáva sa s armádou nástrojov schopných krájať a nakrájať množinu údajov s extrémnou ľahkosťou. Dúfajme, že to bude slúžiť ako odrazový mostík na vašej ceste vpred.
Odporúčané články
Toto je sprievodca údajovým rámcom Python-Pandas. Tu diskutujeme o krokoch k vytvoreniu dátového rámca python-pandas spolu s jeho implementáciou kódu. Ďalšie informácie nájdete aj v nasledujúcich článkoch -
- Top 15 funkcií Pythonu
- Rôzne typy súprav Python
- Top 4 typov premenných v Pythone
- Top 6 editorov Pythonu
- Polia v štruktúre údajov